
Literature | EAPS | Can ChatGPT reduce human financial analysts’ optimistic biases?

封面来源:ChatGPT-4 DALL·E
摘要:本文探究了大语言模型ChatGPT作为上市公司业绩预测财务顾问的潜力。利用中国证券指数300成分股,将ChatGPT对主要财务业绩指标的预测与人类分析师的预测和真实值进行比较,结果表明ChatGPT可以纠正人类分析师的乐观偏见。
引用:Li, X., Feng, H., Yang, H., & Huang, J. (2024). Can ChatGPT reduce human financial analysts’ optimistic biases?. Economic and Political Studies, 12(1), 20-33.
文献:
Introduction
本文研究了ChatGPT预测上市公司业绩方面的能力,以及ChatGPT是否可以减少人类分析师的乐观偏见。
尽管ChatGPT主要是一种语言模型,不是专门为财务决策设计的(Ko and Lee Citation, 2023),但其高效提取和处理广泛信息的能力使其适合担任财务顾问。
分析师预测涉及密集的信息提取和处理活动,在这些活动中,机器具有比人类更高的计算效率(Boyacı et al., 2024),研究一致表明,机器或机器增强分析师在收益和股价预测方面优于人类(Chen et al., 2024; Coleman et al., 2022; Cao et al, 2023)。因此,作者预计ChatGPT能够产生比人类分析师更准确的预测。
此外,本文还探索了提高预测准确性的机制。人类分析师经常表现出乐观的偏见,这源于其参与预测过程和利益冲突。然而,机器是公正的并且受人类偏见的影响较小。这些偏差可以解释许多异常现象,并且可能与记忆过程有关。本文认为ChatGPT预测公司业绩的卓越能力源于减轻人类分析师的乐观偏见。
使用ChatGPT的prompt方式预测2021年至2023年CSI 300指数成分股的业绩,然后将其预测与人类分析师的预测和实现的业绩进行比较(同样为2021年9月前)。关注七个主要的财务绩效指标,即市盈率(PE)、市净率(PB)、每股收益(EPS)、资产回报率(ROA)、净资产收益率(ROE)、收入增长和利润增长。
作者发现ChatGPT在所有绩效维度和预测范围(即2021年、2022年和2023年末)上都比人类分析师更加保守。
本文在回归中量化了由ChatGPT纠正的人类乐观偏见:
- 使用向上预测误差(upward forecast errors)(计算为预测值与实现值之间的差异)作为因变量;
- 将预测误差与ChatGPT虚拟变量(指示预测是否由ChatGPT发布)进行回归;
文献综述
三个角度:financial concept comprehension, academic use, and investment decision-making.
金融概念理解
理解财务和会计概念
ChatGPT 可以准确解释阿尔法值、众筹、另类金融、金融风险、金融危机、巴塞尔框架和银行产品等金融概念(Wenzlaff and Spaeth 2022;Hofert 2023;Lakkaraju et al. 2023;Ren、Lee 和 Hu 2023;Yue et al. 2023),尽管其对数学事实的阐述需要改进(Hofert 2023);
Niszczota 和 Abbas(2023)研究了 ChatGPT 是否有能力充当财务顾问,发现它比随机猜测的人类投资者表现出更高水平的金融素养;
总体而言,ChatGPT 与金融专业人士相当,并且表现出高水平的准确性和专业知识(Ren、Lee 和 Hu 2023);
在类似的环境中,Wei、Wu 和 Chu (2023) 发现 ChatGPT 对审计问题的回答模仿了经验丰富的财务审计师的回答。
解释专有名词
- Ren、Lee 和 Hu(2023)表明,ChatGPT 对财务和会计问题的回答比人类专家的回答更容易被外行人理解;
- Neilson(2023)提供了更直接的证据,表明 ChatGPT 可以向非专业人士推荐养老金缴款计划;
- Yue 等人(2023)通过向 ChatGPT 提出问题或给予指导,例如“向我的祖母解释金融中阿尔法的含义”,当给定受众指示时,ChatGPT 可以进一步定制其解释的复杂性;
- 尽管有其优点,Lakkaraju 等人 (2023) 和 Neilson (2023) 警告ChatGPT在数字推理方面可能存在局限性、其不一致以及对各种相关问题(例如当地监管要求)的无知。
学术用途
- ChatGPT 的表现证据因它所承担的具体工作而异。 ChatGPT 在编码支持、数据分析和结果解释方面表现出色(Alshater 2022;Dowling 和 Lucey 2023;Feng、Hu 和 Li 2023;Korinek 2023);
- ChatGPT在文献综合、测试框架开发、特定领域专业知识和创意起源方面的表现并不令人满意(Alshater 2022;Dowling 和 Lucey 2023)。
投资决策
前期研究
- 关于 ChatGPT 在零样本环境下对金融文本的理解和解释,文献尚无定论(即提示中没有提供预期响应的示例);
- 结论A:
- ChatGPT 在提取新闻、Fedspeak 2、和公司披露中的观点和情绪方面准确且高效(Hansen 和 Kazinnik 2023;Jha 等人 2023);
- 结论B:
- 其他人则声称 ChatGPT 在金融命名实体识别 (FinNER) 和情感分析等任务中表现不佳(Lan 等人,2023 年;Li 等人,2023 年);
- 王等人 (2023) 证明评估 ChatGPT 的性能很复杂:它会生成合理的答案,但可能并不总是与给出的提示相关;然而,与此同时,它在情感分析中优于 Transformer (BERT) 模型的微调双向编码器表示;
- 对相互矛盾的结果的一种可能解释可能是使用了不同的数据源和绩效衡量标准,仅依赖一个数据集的研究往往会高估 ChatGPT 的性能(Jha 等人,2023 年;Hansen 和 Kazinnik,2023 年),而使用多个数据集和不同任务的研究则观察到更多其局限性(Li 等人,2023 年;Wang 等人)等2023)。
近期研究
最近的论文通过直接检验 ChatGPT 是否可以从投资决策的金融背景中提取价值相关信号来扩展这一文献;
优势
$\color{blue}{Lopez-Lira\ and\ Tang\ (2023)}$使用ChatGPT对股票新闻标题进行情绪分析,将新闻分类为好、坏或无关,每个股构建了“ChatGPT 分数”,并发现其与随后的每日股票回报呈正相关;
$\color{blue}{Kim\ et\ al.\ (2023)}$通过==ChatGPT总结管理层讨论和分析、年度报告和收益电话会议中包含的信息,并生成带有明显情绪的精炼摘要,精炼后的摘要对披露日异常收益表现出比原文更显着的解释力==。
局限性
- $\color{blue}{Xie\ et\ al.\ (2023)}$使用ChatGPT==通过输入历史股票价格来预测未来股票走势的方向,结果表明:ChatGPT 的性能较差==(因为预测不如逻辑回归准确)。
投资实战
- $\color{blue}{Ko\ and \ Lee\ (2023)}$将ChatGPT应用于投资,发现ChatGPT的表现优于随机选择的投资组合;
- $\color{blue}{Chen\ et\ al.\ (2023)}$使用三阶段程序,提供了有关ChatGPT如何利用其提取的信息来实现卓越投资业绩的进一步证据:
- 首先,向ChatGPT 提供财经新闻提示,并询问哪些公司受到正面或负面影响;
- 然后,==构建可视化关系的图表==;
- 最后,他们使用机器学习方法,包括图神经网络和长短期记忆神经网络,以比 ChatGPT 更高的准确度来预测股价走势。
[^ 2]: Fedtalk是美国联邦储备委员会(Fed)就货币政策决策进行沟通时使用的技术语言。Hansen和Kazinik(2023)表示,ChatGPT能够将美联储的声明分为鹰派或鸽派。
数据
数据描述
CSI 300指数被广泛认为是中国股市广泛走势的综合指标($\color{blue}{Hou\ and\ Li,\ 2014}$)
The CSI 300 was introduced on 8 April 2005 by the Shanghai and Shenzhen stock exchanges. It consists of the 300 most actively traded Chinese A-share stocks, which account for over 70% of the combined market capitalisation of the two exchanges. The index is widely recognised as a comprehensive indicator of broad movements in the Chinese stock markets ($\color{blue}{Hou\ and\ Li,\ 2014}$).
沪深300指数成分股
采用七种公司绩效衡量标准:
- 股票估值:
- PE(按股价除以每股收益计算)
- PB(按股价除以每股账面价值计算)
- 盈利能力
- 利润除以已发行股票(EPS)
- 净利润除以总资产(ROA)
- 净利润除以总权益(ROE)
- 公司增长
- 收入增长率
- 利润增长率
- 股票估值:
Prompt
输入个股名称和股票代码,并要求ChatGPT预测2021年、2022年和2023年末的PE、PB、EPS、ROA、ROE、收入增长和利润增长。
ChatGPT的回复是高度依赖于提示,而提示本质上是用户的问题。 $\color{blue}{Korinek\ (2023) }$发现提示中的微小调整可能会导致不同的结果。因此,我们尝试不同的提示来检索所需的结果。遵循 OpenAI 3和$\color{blue}{M\ Alshater\ (2022) }$ 的指导,构建提示如下:
1 | Provide a table of price-to-earnings (P/E) forecasts at the end of 2021, 2022 and 2023 for the firms below, as of September 2021: |
提示尽可能清晰,明确指定了度量、时间范围、公司和截至时间。在没有时间范围的情况下,ChatGPT会以截至 2021年9月的最新实现值进行响应。在没有截至时间的情况下,ChatGPT拒绝分配并解释其无法提供2021年9月之后的信息。ChatGPT做出的预测是:仅当提示包含时间范围和当前时间时我们才需要。我们要求的表格输出格式隐藏了ChatGPT对每个公司未来业绩的语言分析,并仅保留预测值 4。使用分隔符划分提示:使用一个换行符指示公司,使用两个换行符指示指令和公司列表。
单个提示-响应对中存在上下文长度限制,将 300 家样本企业分为 10 批,每批 30 家企业。相当小的批量大小避免长度溢出,并消除了公司内部(跨范围)预测中断和恢复提示干扰所引入的偏差,从而使预测能够继续。
在某些文本生成任务中,少量提示或在提示中提供对话示例可以提高生成质量。通过采用零样本提示而不是少样本提示,我们采取严格中立的立场,并且不会因人类预测示例而对 ChatGPT 产生偏见($\color{blue}{Zhao\ et\ al.\ 2021}$)。当进行下一个绩效衡量时,总是开始新的聊天,以确保输出不会受到先前指令的影响。
另一个挑战是,即使多次给出相同的提示,ChatGPT 也可能会产生略有不同的预测。幸运的是,尽管存在细微差异,但结果高度相似且具有可比性($\color{blue}{Ko\ and \ Lee,\ 2023}$)。为了减轻一代特质,本文独立重复该过程 35 次并取平均值 5。 使用该方法提供了对300家公司七项指标的三年预测。
从CSMAR数据库获取金融分析师的预测,为了确保人类分析师和ChatGPT使用可比较的信息集,将人类预测限制为2021年9月前发布的预测。一些报告提供了不同时间范围的预测。作者从582份分析师报告中总共获得了10550个预测年观察结果。真实数据来自CSMAR和Wind,但仅有2021年和2022年的数据,在撰写本文时还没有2023年的数据。
3. Available at: https://platform.openai.com/docs/guides/gpt-best-practices. ↩
4:ChatGPT can provide reasons using human-like language on why it issues such forecasts along with the forecasted values, which basically include analyses of a firm’s fundamental outlook. In this paper, we keep the forecasted values only by requesting the table output format. ChatGPT可以使用类似人类的语言提供理由,说明它为什么发布这样的预测以及预测值,其中基本上包括对公司基本前景的分析。在本文中,我们仅通过请求表输出格式来保持预测值。
5:For instance, ChatGPT’s 35 forecast responses for the PE of Kweichow Moutai at the end of 2021 are 28.5, 39.2, 33.8, 34.8, 29.1, 32.1, 33.5, 34.2, 34.3, 34.5, 34.2, 33.2, 34.2, 34.6, 37.2, 35.2, 39.2, 27.4, 43.2, 39.2, 37.5, 32.8, 30.2, 42.3, 35.4, 30.5, 41.2, 34.6, 35.2, 36.7, 28.2, 35.2, 38.1, 38.2, and 40.1. We calculate the average, 35.1, as the final forecast.
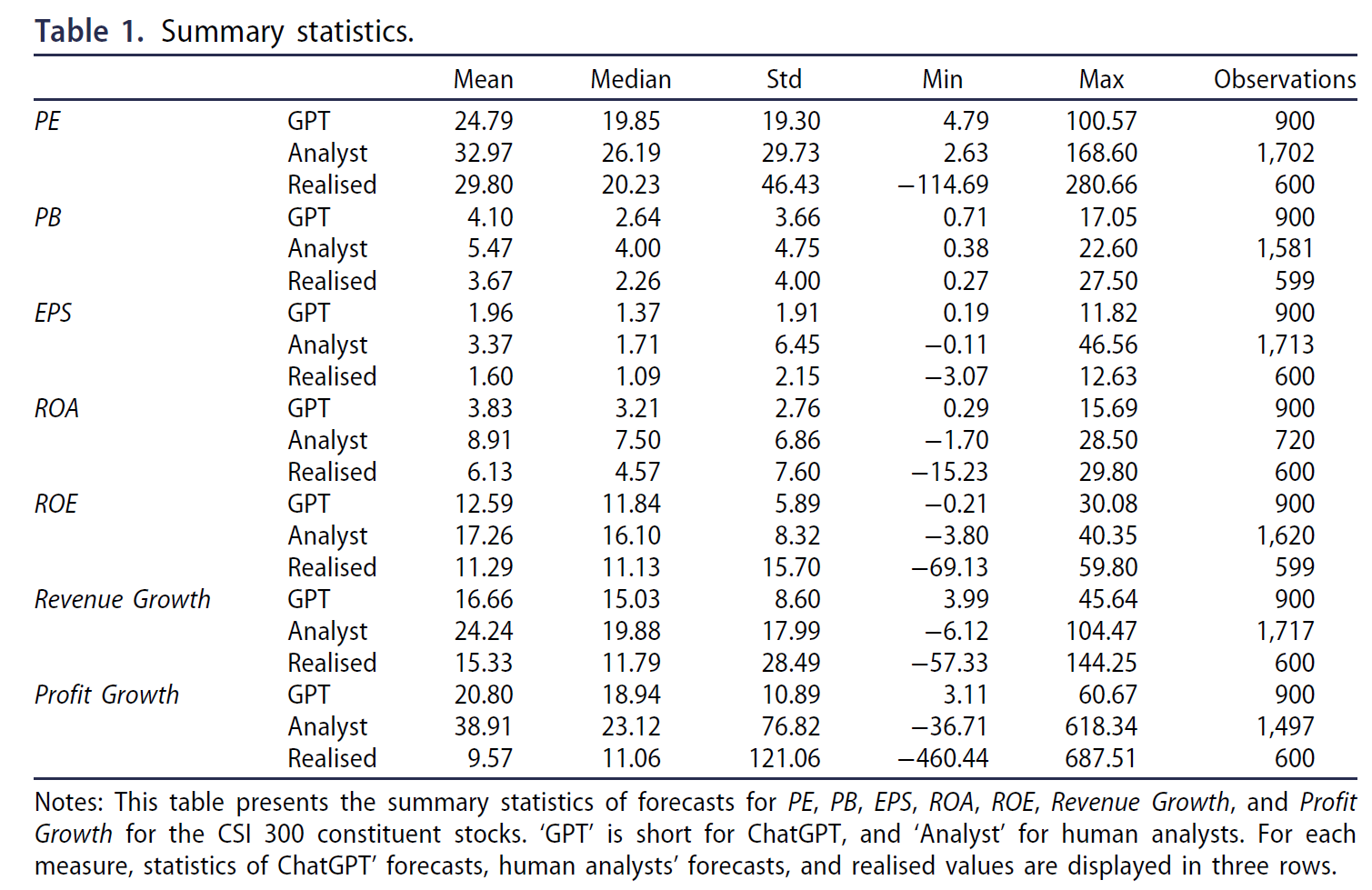
$\color{purple}{表\ 1}$列出了ChatGPT预测、人类分析师预测以及真实值的汇总统计数据,每个指标分三行显示。
- 第一行包含 ChatGPT 的预测,包含 900 个观察值(3 年 × 每年 300 家公司);
- 第二行包含人类分析师的预测;
- 最后一行包含已实现绩效的 600 个观察值(2 年 × 每年 300 家公司) 。
- 由于我们样本中的许多股票都有多个分析师团队跟踪,因此人类分析师对某一年的预测可能不止一个。因此,人类分析师预测的样本可能会超过 900 个。此外,分析师报告可能不包括所有七个指标,导致不同绩效指标的观察数量不平衡 6。
$\color{purple}{表\ 1}$揭示了四种值得注意的模式:
- 首先,ChatGPT 的平均预测值和中值预测值在所有七项指标中均低于人类分析师的预测值;
- 其次,人类分析师始终表现出向上的偏见;
- 第三,除了PE的预测外,ChatGPT的预测值更接近实际值;
- 第四,ChatGPT的预测错误是双向的:高估了PB、EPS、ROE、收入增长和利润增长,但PE和ROA的预测值低于实现值;
- $\color{purple}{表\ 1}$中的汇总统计数据与我们的猜想一致,即ChatGPT通过减少乐观偏见而优于人类分析师。
上述结果将不同时间范围的预测汇总在一起,因此很难解释差异。
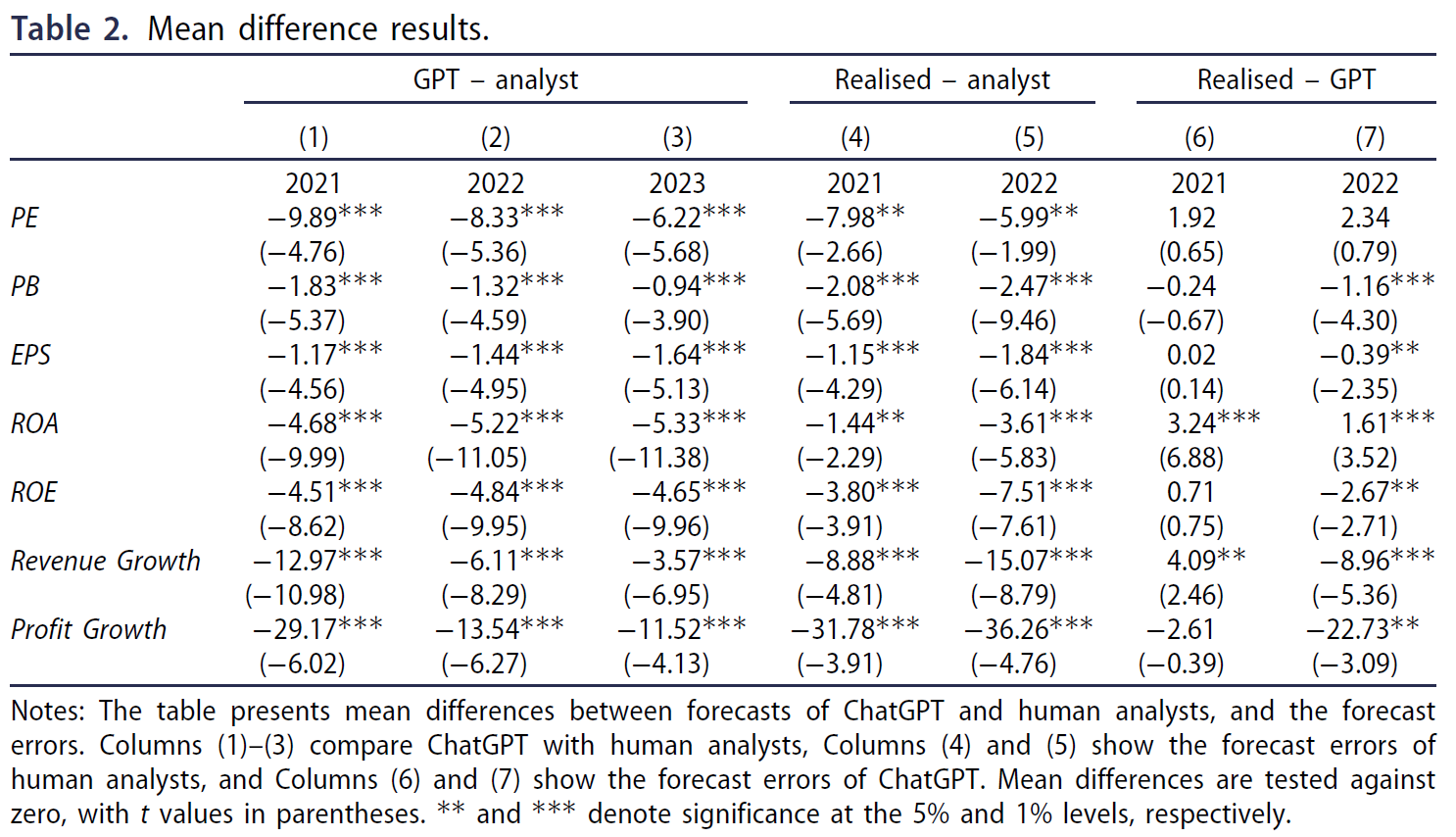
$\color{purple}{表\ 2}$:
- 对第 (1)-(3) 列中 ChatGPT 和人类分析师之间的每个指标和每个时间范围执行均值差 t 检验,发现有证据表明人类分析师比 ChatGPT 更乐观;
- 在第 (4) 和 (5) 列中,将人类分析师的预测与真实值进行比较;
- 只有 2021 年和 2022 年的结果,因为 2023 年的实现绩效数据尚未提供;
- 人类分析师显着高估了所有绩效指标,并且向上偏差的程度随着时间的推移而增加。
- 相比之下,ChatGPT 对 2021 年没有表现出任何乐观偏见(第 (6) 列);除了略微低估的 ROA 和收入增长之外,其预测与五项指标的实际表现没有显着差异;
- 然而,ChatGPT 的准确性在 2022 年的长期范围内不会持续存在;
- 第 (7) 列中的预测误差在七个绩效指标中的六个中显着非零(PE 除外);
- ChatGPT 高估了七项指标中的五项,但偏差比人类分析师的偏差要少得多;
6. One potential problem in Table 1 is that it uses 2021–2023 forecasts from ChatGPT and human analysts, but only 2021–2022 data for realised performance. In unreported results, we exclude ChatGPT’s and human analysts’ forecasts for 2023 and find consistent patterns. ↩
Empirical results
回归量化 ChatGPT 纠正的人类分析师的乐观偏见,使用 ChatGPT 和人类分析师对 2021 年和 2022 年预测的完整样本(即 2021 年底和 2022 年公司业绩的预测值)。因变量是向上预测误差,计算为预测 $E(y)$ 与真实值$y$之间的差异。解释变量是虚拟变量ChatGPT,表明预测由 ChatGPT 还是人类分析师发布。
包括一组与文献中记载的分析师预测误差相关的因素的控制变量。 $\color{blue}{Abarbanell\ (1991)}$表明,分析师的预测没有完全纳入过去的股票价格信息,并且效率不够,意味着价格上涨预示着向下偏差的预测误差。为了控制这种影响,将 2021年9月之前52周的年化收益率纳入其中。
不确定性会影响预测误差(Das、Levine 和 Sivaramakrishnan 1998;Lim 2001)。分析师倾向于发布有利于公司的预测,以换取管理团队的私人信息。继 Lim(2001)之后,我们使用 2021 年 9 月之前 52 周的年化波动率作为基于市场的不确定性控制。
分析师在预测长期业绩方面表现不佳(Harris 1999)。预测误差随着时间范围的增加而增加,这意味着分析师更难准确预测更遥远的未来的表现。参考Dong et al. (2021) 和 Bolliger (2004),本文控制了预测范围。
随着公司的老化,市场会积累更多有关公司的信息。 Maskara and Mullineaux(2011)表明,预测误差和企业年龄都与信息不对称有关。参考 Amir、Lev and Sougiannis(2003),本文将公司年龄作为控制变量。
此外,所有权结构会影响分析师的预测误差(Ackert 和 Athanassakos,2003),特别是在中国资本市场的独特环境下(Huang 和 Wright,2015;Liu,2016),国有企业和非国有企业之间存在明显区别。 我们包括一个控制变量来表明公司是否国有。
最后,我们遵循 Ali、Klein and Rosenfeld (1992)、Cen、Hilary and Wei (2013)、So (2013) 和 Dong et al.(2021)的做法,纳入了滞后的企业特征指标。
回归方程如下:
其中,下标表示第$t$年的公司$i$和绩效指标$j$。
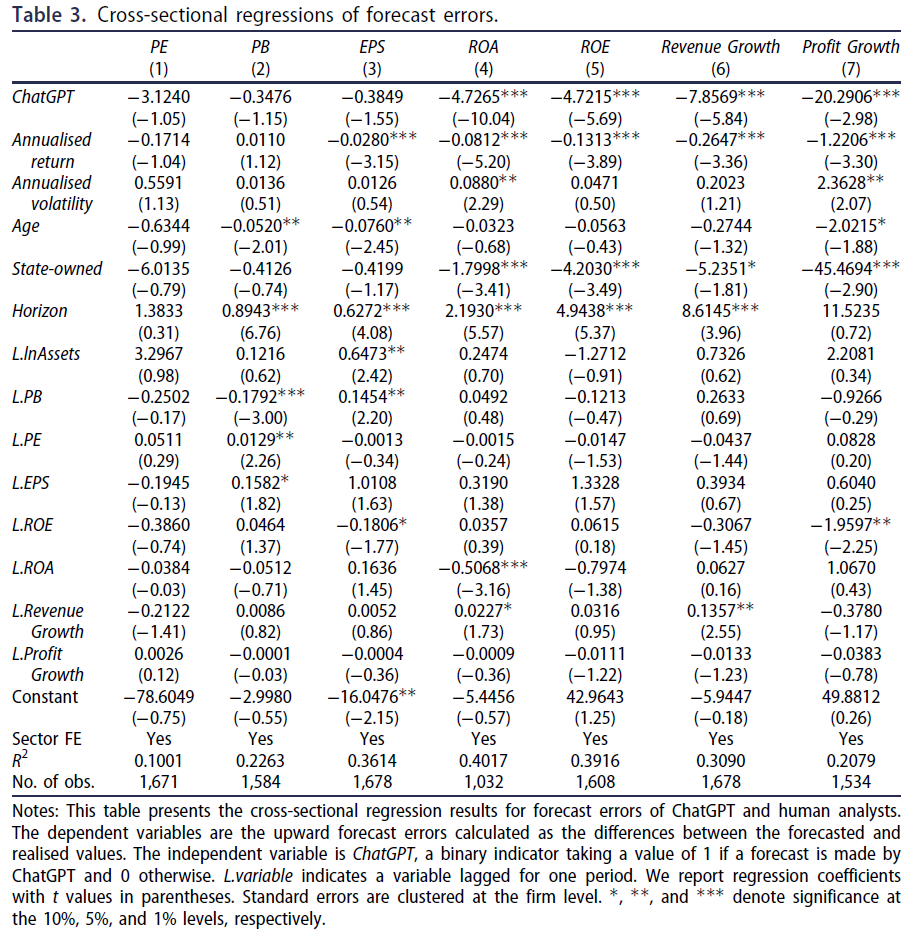
$\color{purple}{表\ 3}$列出了横截面回归结果。相较人类分析师,ChatGPT 在七项指标中的四项(ROA、ROE、收入增长和利润增长)中表现出明显较少的乐观偏差。当因变量为 PE、PB 和 EPS 的向上预测误差时,ChatGPT 的系数也为负(但不显著),这些结果与表 2 中的均差$t$检验结果一致。有关控制变量的结果也符合预期。乐观偏差随着预测范围的增加而增加,并随着预测时的年化收益而减少,这与 Abarbanell (1991) 的发现是一致的。The optimistic biases increase with the forecast horizon and decrease with the annualised return at the time when the forecast is made, which is consistent with the finding of Abarbanell (Citation1991).
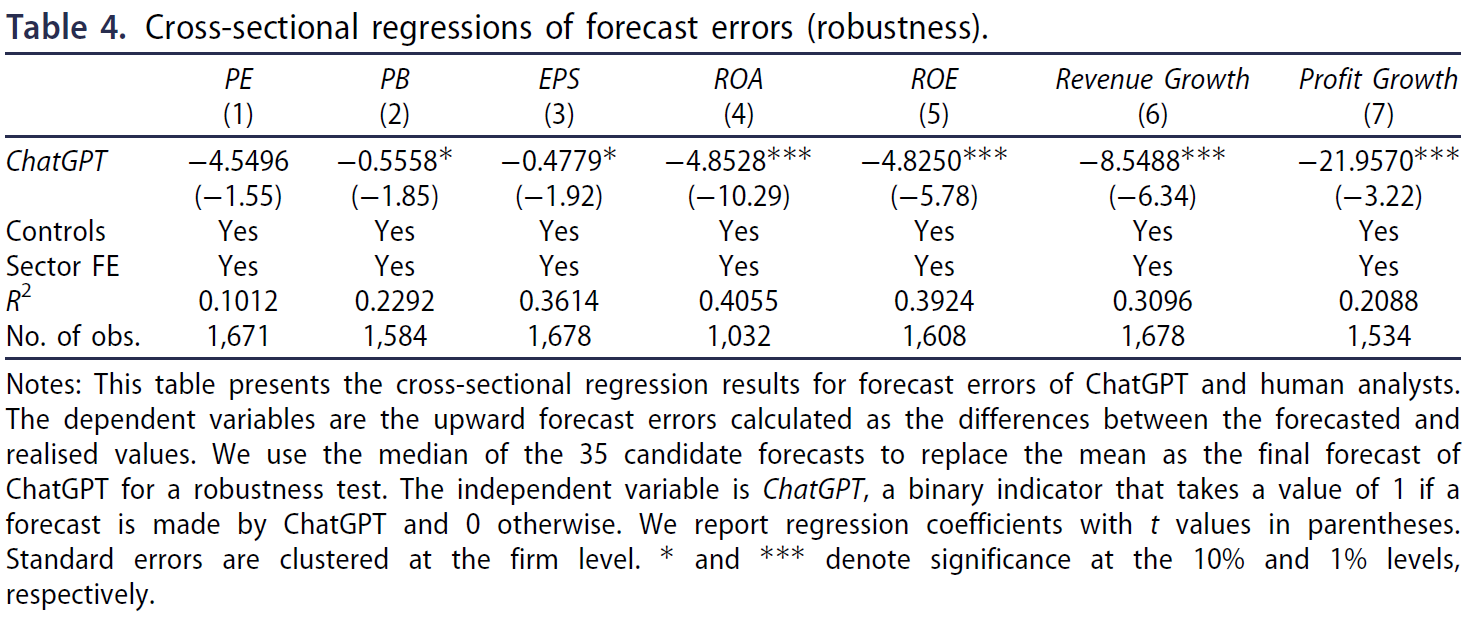
受Adiwardana et al. (2020)提出了样本排序方法的启发,本文通过选择置信度最高的预测进行稳健性测试以解决 ChatGPT 预测中的随机性。在样本排序方法中,LLM 选择具有最高预测概率的候选文本序列作为最终输出。遵循同样的思路,选择 35 个响应的中位数作为 ChatGPT 的最终预测。
$\color{purple}{表\ 4}$中报告了稳健性检验,结果优于$\color{purple}{表\ 3}$,可观察到 ChatGPT 在七个维度中的六个维度上减少了人类分析师的乐观偏见,PE 是唯一的例外。
Conclusion
本文利用 ChatGPT(LLM)来预测CSI 300 指数公司的业绩,并将其预测与 2021 年 9 月发布的人类分析师的预测进行比较,该日期恰逢 ChatGPT 训练集截止日期。通过使用真实值作为基准,发现 ChatGPT 的表现稳定优于人类分析师,实现更小的向上预测误差。人类分析师倾向于提供乐观的预测,而 ChatGPT 则更为保守。 ChatGPT 预测的卓越准确性可归因于它能够纠正人类分析师预测中固有的乐观偏差。
我们认为 ChatGPT 等 LLM 应用程序并不意味着从根本上取代人类金融分析师。相反,ChatGPT 可以协助和改进人力财务预测。在本文中,我们提供了 ChatGPT 预测财务业绩和减少人类乐观偏见能力的证据,这表明 ChatGPT 具有协助分析师和投资者的潜力。 ChatGPT 有望减少人类分析师的过度自信或利益冲突。需要注意的是,我们警告不要过度扩展我们的结果,因为投资者不应仅仅依赖 ChatGPT,也不应将其预测用作“正确”答案。 ChatGPT 平均优于人类分析师的结果并不意味着它总是比人类分析师更准确。我们将我们的发现解释为证明了 ChatGPT 在补充人类分析师和投资者预测方面的价值。由于本文是揭示 ChatGPT 和人类分析师之间预测差异的首次尝试,我们鼓励未来的研究人员深入探讨这些差异的原因。
这项研究有一定的局限性,这也给我们的读者敲响了警钟。首先,分析仅涵盖了短期的两年预测;因此,在考虑广泛的市场动态时,这是不够的。因此,需要更多证据来证明 ChatGPT 跨长周期的预测性能。较短的时间跨度引发了人们对我们研究结果的普遍性的担忧,特别是当市场条件发生变化时。随着数据可用性的增加,未来的研究人员应该将 ChatGPT 的预测与人类分析师在更长的历史跨度上的预测进行比较。
其次,由于 LLMs 的黑匣子性质,我们对 ChatGPT 进行财务预测并以比人类更少的乐观偏差来提供预测的内部流程知之甚少。可能的渠道可能包括 ChatGPT 处理基本信息和综合信念的卓越能力和/或其与人类相比更高的公正性。这一限制表明了未来研究的另一个方向,即利用新颖的研究设计并揭示 ChatGPT 的内部机制,通过该机制可以减少乐观偏差的预测。
总之,本文提供了 ChatGPT(越来越多的 LLMs 之一)在预测上市公司业绩方面的应用的经验证据,并强调了 ChatGPT 在提供财务建议方面的潜力。此外,我们的结果阐明了 LLMs 在减轻金融决策中的人类偏见方面的作用。展望未来,未来的研究人员可能会考虑探索 LLMs 在金融领域的其他应用,并研究其在各种决策环境中的有效性。
参考文献
- Ko, H., & Lee, J. (2023). Can chatgpt improve investment decision? from a portfolio management perspective. From a portfolio management perspective. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4390529.
- Boyacı, T., Canyakmaz, C., & de Véricourt, F. (2024). Human and machine: The impact of machine input on decision making under cognitive limitations. Management Science, 70(2), 1258-1275.
- Chen, X., Cho, Y. H., Dou, Y., & Lev, B. (2022). Predicting future earnings changes using machine learning and detailed financial data. Journal of Accounting Research, 60(2), 467-515.
- Coleman, B., Merkley, K., & Pacelli, J. (2022). Human versus machine: A comparison of robo-analyst and traditional research analyst investment recommendations. The Accounting Review, 97(5), 221-244.
- Kim, A. G., Muhn, M., & Nikolaev, V. V. (2023). Bloated disclosures: can ChatGPT help investors process information?. Chicago Booth Research Paper, (23-07). https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4425527.
- Xie, Q., Han, W., Lai, Y., Peng, M., & Huang, J. (2023). The wall street neophyte: A zero-shot analysis of chatgpt over multimodal stock movement prediction challenges. arXiv preprint arXiv:2304.05351.
- Ko, H., & Lee, J. (2023). Can chatgpt improve investment decision? from a portfolio management perspective. From a portfolio management perspective. Available at SSRN 4390529. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4390529.
- Chen, Z., Zheng, L. N., Lu, C., Yuan, J., & Zhu, D. (2023). ==ChatGPT informed graph neural network for stock movement prediction==. arXiv preprint arXiv:2306.03763.
- Hou, Y., & Li, S. (2014). The impact of the CSI 300 stock index futures: Positive feedback trading and autocorrelation of stock returns. International Review of Economics & Finance, 33, 319-337.
- M Alshater, M. (2022). Exploring the role of artificial intelligence in enhancing academic performance: A case study of ChatGPT. Available at SSRN 4312358. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4312358.
- Korinek, A. (2023). Language models and cognitive automation for economic research (No. w30957). National Bureau of Economic Research. https://www.nber.org/papers/w30957.
- Zhao, Z., Wallace, E., Feng, S., Klein, D., & Singh, S. (2021, July). Calibrate before use: Improving few-shot performance of language models. In International conference on machine learning (pp. 12697-12706). PMLR. http://proceedings.mlr.press/v139/zhao21c.html.
- Abarbanell, J. S. (1991). Do analysts’ earnings forecasts incorporate information in prior stock price changes?. Journal of Accounting and Economics, 14(2), 147-165.
 微信
微信 支付宝
支付宝




