
Draft | Can ChatGPT forecast stock price movements?

封面来源:ChatGPT-4 DALL·E
摘要:本文研究了ChatGPT和其他大型语言模型在使用新闻标题预测股市收益方面的潜力。通过ChatGPT判断新闻标题对公司股价所产生的积极、中性和消极作用,产生的得分与随后的每日股票收益之间显著正相关。尽管ChatGPT优于传统的情绪分析方法,然而GPT-1、GPT-2和BERT等更基本的模型无法准确预测收益,基于ChatGPT-4的长短期策略可获得最高的夏普比率,这说明收益的可预测性是复杂语言模型的一种新兴能力。此外,小盘股和大盘股均具有可预测性,这表明市场对公司新闻的反应不足。较小的股票和有坏消息的股票的可预测性更强,这与套利限制也起着重要作用的观点一致。总之,将先进大语言模型纳入投资决策更精准预测,并提高量化交易策略的性能。
引用:Lopez-Lira, A., & Tang, Y. (2023). Can chatgpt forecast stock price movements? return predictability and large language models. arXiv preprint arXiv:2304.07619. https://doi.org/10.48550/arXiv.2304.07619.
文献:
Introduction
引言
有限套利或称套利限制是指由于风险、成本、信息不对称和制度性约束等因素的影响,使得套利者的套利行为受到限制。 现有研究发现,套利限制会影响投资者的交易活动,使更多错误定价信息融入到交易中去,进而导致资产价格偏离其基本价值,加剧市场的错误定价和价格波动(Lam和Wei,2011;Gu等,2018)。
金融经济领域,尤其是预测股市收益能力,使用LLMs仍然是一个相对未知的领域。LLMs预测金融市场走势表现如何是一个悬而未决的问题,本研究旨在通过LLMs提取新闻标题中的上下文预测股票收益方面的潜力填补空白。
如$\color{blue}{Tetlock(2007)}$、$\color{blue}{Tetlock\ et\ al.(2008)}$ 和 $\color{blue}{Tetlock(2011)}$ 使用新闻和训练的算法成功预测股票收益,可能是因为组合新信息很复杂($\color{blue}{Fedyk\ and\ Hodson,2023}$)。
具体做法:
- 本文通过利用大语言模型分析新闻标题情绪,比较包括ChatGPT在内的各种LLM的性能,并将其与领先数据供应商提供的现有情绪分析方法进行比较;
- 对于每个标题,使用ChatGPT来判断其对公司股价的作用是’good’、’bad’还是’neutral’,并转换为分数预测下一个交易日的股票收益;
实证发现:
- ChatGPT优于传统情绪分析方法;
- GPT-1、GPT-2和BERT等更基本的模型预测股票的能力较弱,ChatGPT-4观察到最高的可预测性;
- 样本期内ChatGPT-4获得最高的夏普比率3.8,而基于ChatGPT-3.5策略的夏普比率为3.1;
- ChatGPT可预测性存在于小盘股和大盘股以及具有积极和消极消息的股票中,市场似乎对公司新闻反应不足,这与现有文献中的观点一致;
- 可预测性在小盘股中更为明显;
进一步工作:
根据以上发现,本研究提出一种新方法估计并理解模型的推理能力。利用模型解释其推理的能力,步骤如下:
- 首先,通过将判断结果(不包括“UNKNOWN”)与第二天的已实现收益进行比较检验判断是否正确;
- 其次,拟合模型,预测判断正确与否。
- 第三,利用模型的特征重要性($\color{blue}{Binsbergen\ et\ al.,2023}$)理解更能准确预测判断的概念;
- 当判断与stock purchases by insiders,earning guidance,dividends有关时,更可能正确;
- 当判断涉及partnerships和developments时,判断准确性降低;
贡献:
- 帮助监管机构和政策制定者了解金融市场越来越多使用LLMs的潜在优势及风险;
- 为资产管理公司和机构投资者提供LLMs在预测股市收益方面的有效性的实证证据;
- 有助于更广泛地讨论人工智能在金融中的应用;
文献综述
Institutional Background
Data
日度收益率:股价、交易量和市值数据(Center for Research in Security Prices (CRSP))
新闻标题
RavenPack
数据
- 周期:2021年10月-2022年12月(as ChatGPT’s training data stops in September 2021)【This ensures that our $\color{red}{evaluation\ is\ based\ on\ information\ not\ present\ in\ the\ model’s\ training\ data}$, allowing for a more accurate assessment of its predictive capabilities.】
- 样本包括在纽约证券交易所(NYSE)、全国证券交易商协会自动报价系统(NASDAQ)和美国证券交易所(AMEX)上市的所有股票,至少有一篇新闻报道被主要新闻媒体或新闻专线报道;
- 分析重点放在股票代码为10或11的普通股上;
数据清洗
- 首先,使用网络抓取为所有CRSP公司收集一个全面新闻数据集;
- 搜索所有包含公司名称或股票代码的新闻,由此产生的数据集包括来自各种来源的新闻标题,如主要新闻机构、财经新闻网站和社交媒体平台;
- 收集样本期内的所有新闻;
- 然后,将标题与知名新闻情绪分析数据提供商(RavenPack)的标题进行匹配【其后段落重点介绍与RavenPack匹配的重要意义】:
- 大多数(超过70%)匹配的标题对应于新闻稿;
- 但不使用RavenPack增强标题;
- 参考$\color{blue}{Jiang\ et\ al.\ (2021)}$预处理方法处理合并后的数据集,匹配了4138家公司的67586个头条新闻;
- 使用数据供应商的“相关性得分”,范围从0到100,指示新闻与特定公司的相关性
- 仅采用相关性得分为100的新闻;
- 限制为完整的文章和新闻稿,并排除归类为“股票上涨”和“股票下跌”的标题 【only indicate the daily stock movement direction】;
- 为了避免新闻重复,要求“事件相似性天数”超过90天,这确保只捕获有关公司的新信息;
- 剔除同一家公司一天内的重复和过于相似的标题:使用最优字符串对齐度量(受限Damerau-Levenstein距离)衡量标题的相似性,删除同一公司一天内相似性大于0.6的标题;
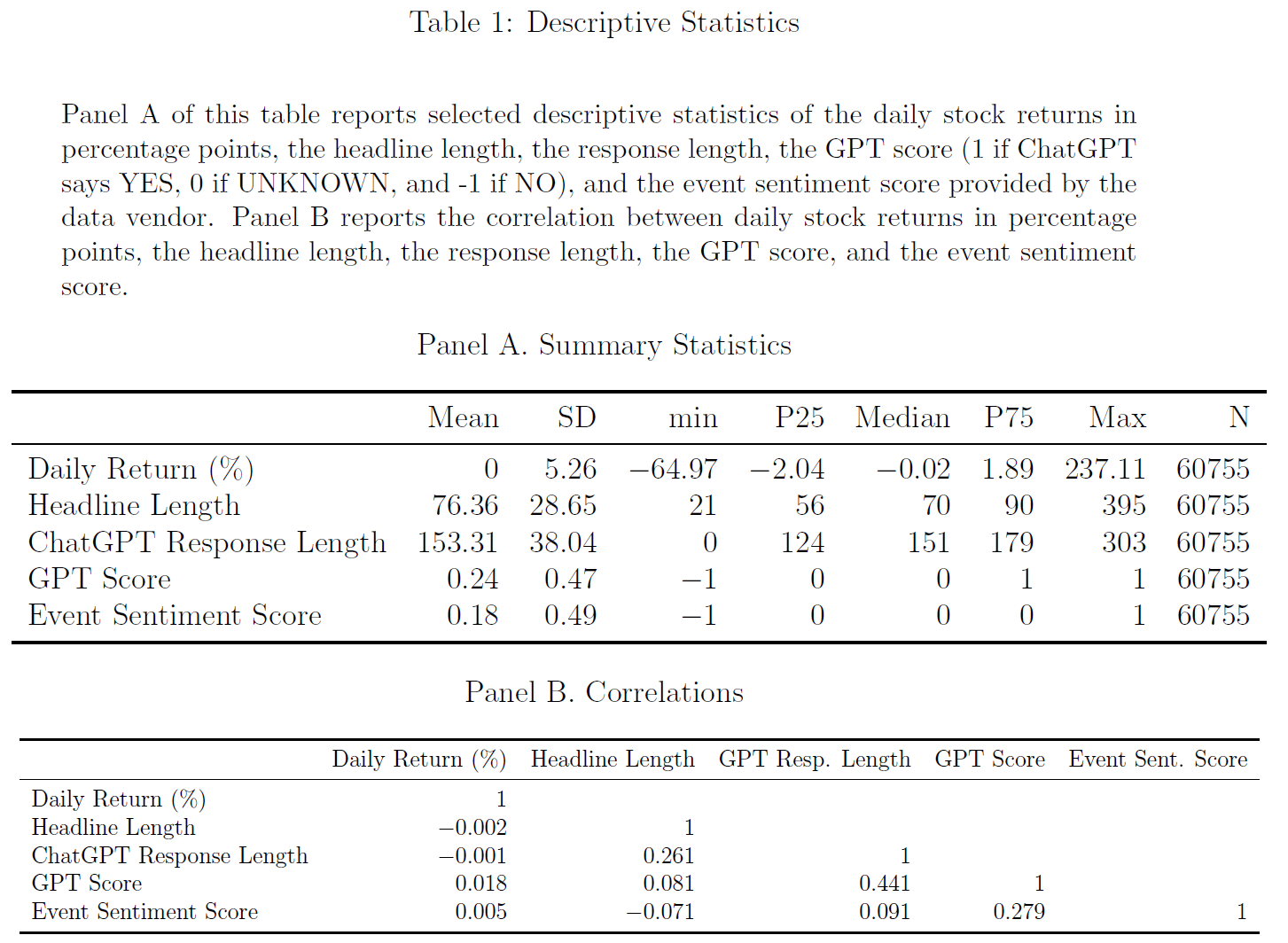
$\color{purple}{Panel A}$表明新闻标题总体上正面;$\color{purple}{Panel B}$报告了变量的相关矩阵,GPT得分与事件情绪得分之间的相关性较低,小于0.28。
方法
Prompt
使用以下提示,并将其应用于公开新闻标题:
1
2Forget all your previous instructions. Pretend you are a financial expert. You are a -financial expert with stock recommendation experience. Answer “YES” if good news, “NO” if bad news, or “UNKNOWN” if uncertain in the first line. Then elaborate with one short and concise sentence on the next line. Is this headline good or bad for the stock price of company name in the term term?
Headline: _headline_如果消息对股价为正面影响,则要求ChatGPT回答“YES”,如果负面消息则回答“NO”,如果不确定则回答“UNKNOWN”;
相对应,“YES”得分为1,“NO”得分为-1,“UNKNOWN”不计分;
举例说明ChatGPT与传统文本分析工具情绪判断差异,$\color{red}{凸显了语境在自然语言处理中的重要性}$,以及在做出投资决策之前仔细考虑新闻标题含义的必要性。【极端,大公司,热点】
Empirical Design
我们将头条新闻与下一个交易时段相匹配。对于交易日早上6点之前的头条新闻,我们假设头条新闻可以在当天开盘时交易,并在当天收盘时出售。对于早上6点之后但下午4点之前的头条新闻,我们假设头条新闻可以在当天收盘时交易,并在下一个交易日收盘时出售。对于下午4点之后的头条新闻,我们假设头条新闻可以按第二天的开盘价交易,并按第二日的收盘价出售。然后,我们对ChatGPT分数、数据供应商提供的情绪分数和其他LLM的分数进行第二天股票收益的线性回归。因此,我们所有的结果都是不样本的。
“YES”得分为1,“NO”得分为-1,“UNKNOWN”不计分;
一家公司在一天内有多个头条新闻,则对分数进行平均;
头条新闻与下一个交易时段匹配:
交易日早上6点之前的头条新闻,假设头条新闻可以在当天开盘时交易、在当天收盘时出售;
早上6点之后但下午4点之前的头条新闻,假设可以在当天收盘前交易,并在下一个交易日收盘时出售;
下午4点之后的头条新闻,假设可以按第二天的开盘价交易,并按第二日的收盘价出售;
回归:
- 其中,$r{i,t+1}$是股票$i$次交易日的收益率,$x{i,t}$指个股依据新闻标题得分;$a_i$和$b_t$分别是公司、日期固定效应,控制任何可观察和不可观察的时不变公司特征以及可能影响股票收益的常见时间特定因素。标准误按日期和公司进行双重聚类。
基本大模型
- 如BERT、GPT-1和GPT-2;
- 将其性能与更高级的模型进行了比较;
- 采用了不同的策略,因为这些模型无法遵循提示回答特定问题(例如,GPT-1和GPT-2是自动完成的模型;更多信息见$\color{purple}{附录B}$);
通过比较基本LLMs和更高级LLMs的性能,理解$\color{red}{收益可预测性为大语言模型的新兴能力}$。
Results
Long-Short Strategies based on ChatGPT Scores
为了评估ChatGPT预测股价走势的能力,首先考察了基于ChatGPT新闻标题得分形成的多空策略的表现。形成零成本投资组合,在新闻发布后购买得分为正的股票,并出售得分为负的股票。
- 如果消息在交易日早上6点之前发布,我们在开盘时进入头寸,在当天收盘时退出;
- 如果消息是在早上6点之后但在收盘前发布的,将以当天的收盘价进入头寸,并在下一个交易日收盘时退出;
- 如果消息是在市场收盘后宣布的,在下个工作日开盘价进入头寸,并在当日收盘时退出;
- All strategies are rebalanced daily.
$\color{purple}{图1}$绘制了不考虑交易成本的七种不同交易策略(投资1美元)的累积收益。七种策略包括:
- 基于ChatGPT 3.5购买有好消息公司的等权重投资组合(“多头”);
- 基于ChatGPT 3.5出售有坏消息公司的等权重投资组合(“空头”);
- 基于ChatGPT 3.5的多空策略(“多空”);
- 基于ChatGPT 4的自筹资金多空策略(“多空GPT 4”);
- 等权重市场投资组合(“市场等权”);
- 市值加权市场投资投资组合(“市值加权”);
- 前一天有消息的所有股票的等权重投资组合,无论消息方向如何(“所有消息”)。
$\color{red}{ChatGPT得分具有预测次交易日股票收益的能力}$
- 不考虑交易成本,2021年10月到2022年12月,基于ChatGPT 3.5的多空策略可获得超过550%的惊人累计收益;
- 等权重和市值加权的市场投资组合以及等权的全新闻投资组合在同一时期都获得了负的累积收益;
- 以上表明,ChatGPT可以通过从新闻标题中提取预测股市反应的有价值信息获得收益;
- “多头”和“空头”都有助于ChatGPT的可预测性。
- “多头”提供了大约200%;
- “空头”提供了超过250%;
- $\color{red}{有坏消息的股票,可预测性更强}$。
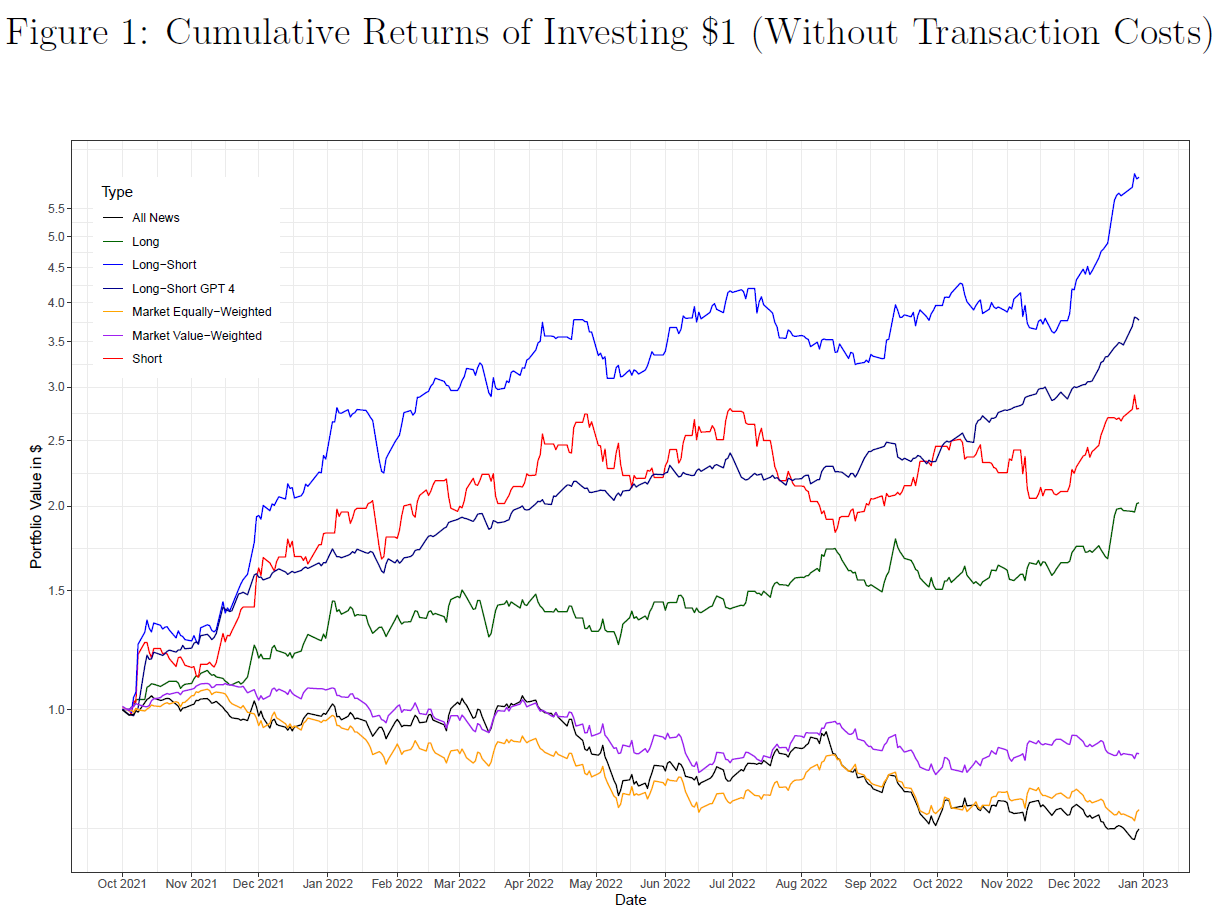
- $\color{purple}{图2}$考虑了不同交易成本假设下ChatGPT 3.5的性能
- 每笔交易5、10和25个基点(bps);
- 即使假设每笔交易的交易成本为5个基点(即往返10个基点),该策略在我们的样本期内仍能获得超过450%的累计收益;
- 随着我们将每笔交易的交易成本提高到10个基点,累计收益率仍高达350%;
- 假设每笔交易的交易成本非常高,为25个基点,则累计收益率将降至50%;
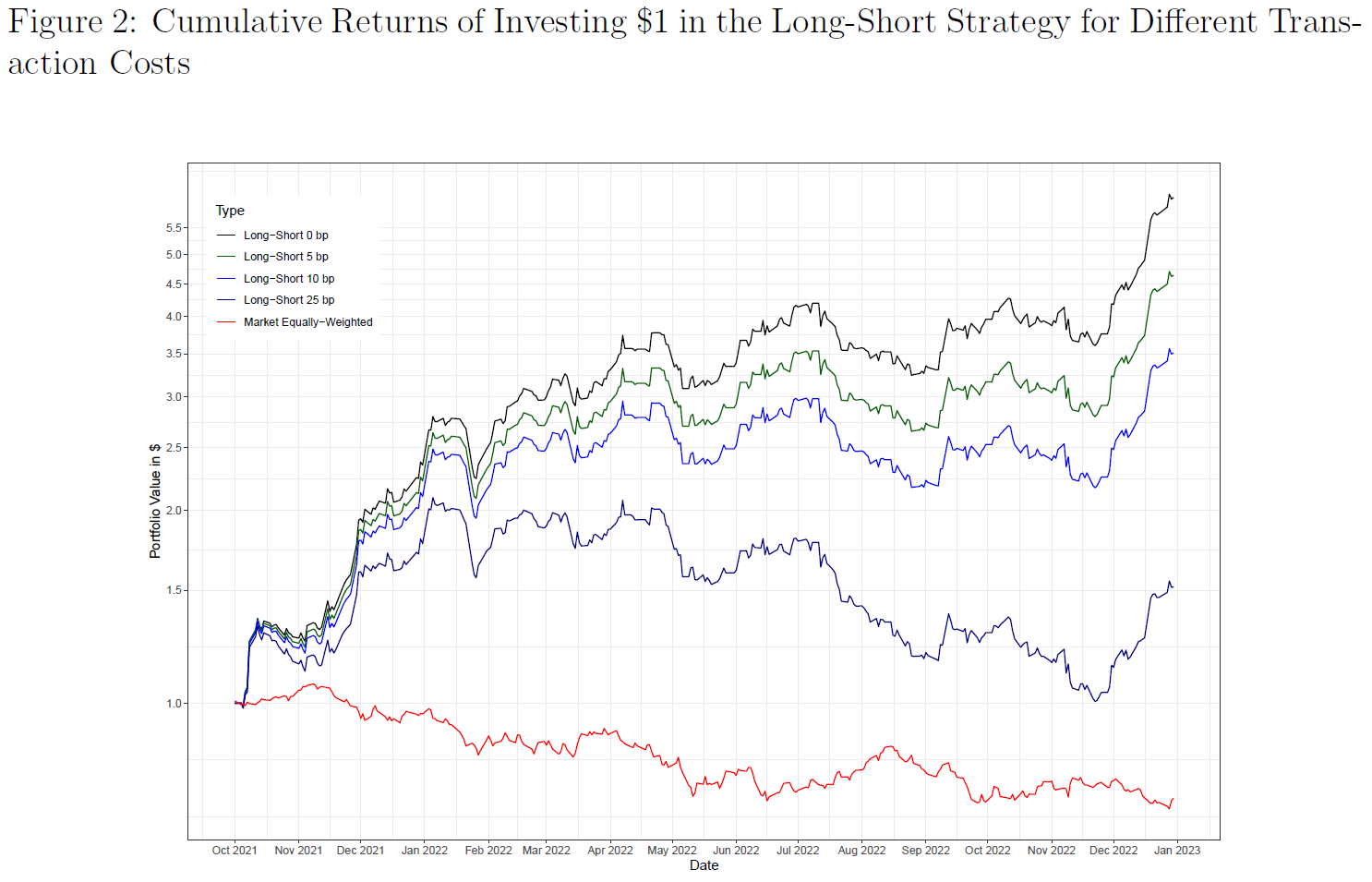
由于“空头”往往提供更高的累积收益,$\color{purple}{图3}$中比较了不同交易成本假设下的预测能力:
- 与“多空”投资组合相比,“空头”投资组合的累积收益对交易成本变化更敏感;
- 将每笔交易的交易成本从0基点增加到25基点,将损失所有250%以上的累积正收益,并转为负,与等权重市场投资组合持平;
ChatGPT 4“多空”策略产生了超过350%的累积收益,明显优于市场投资组合或全新闻投资组合;略低于“空头”和“多头”策略,但随时间变化小得多;
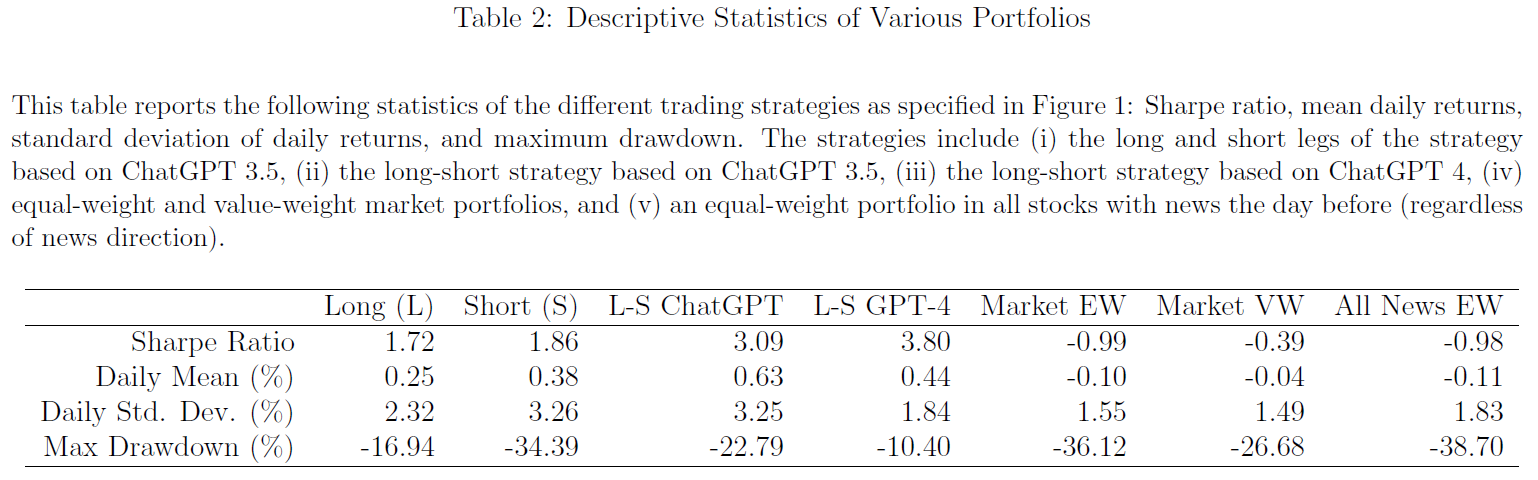
- $\color{purple}{表2}$显示了图1中所示七种不同策略的夏普比率和最大回撤:
- GPT-4“多空”策略提供3.8的夏普比;
- GPT-4“多空”策略的最大回撤为-10.4%;
- $\color{red}{更复杂的模型似乎具有更好的可预测性}$;
Results from Predictive Regressions
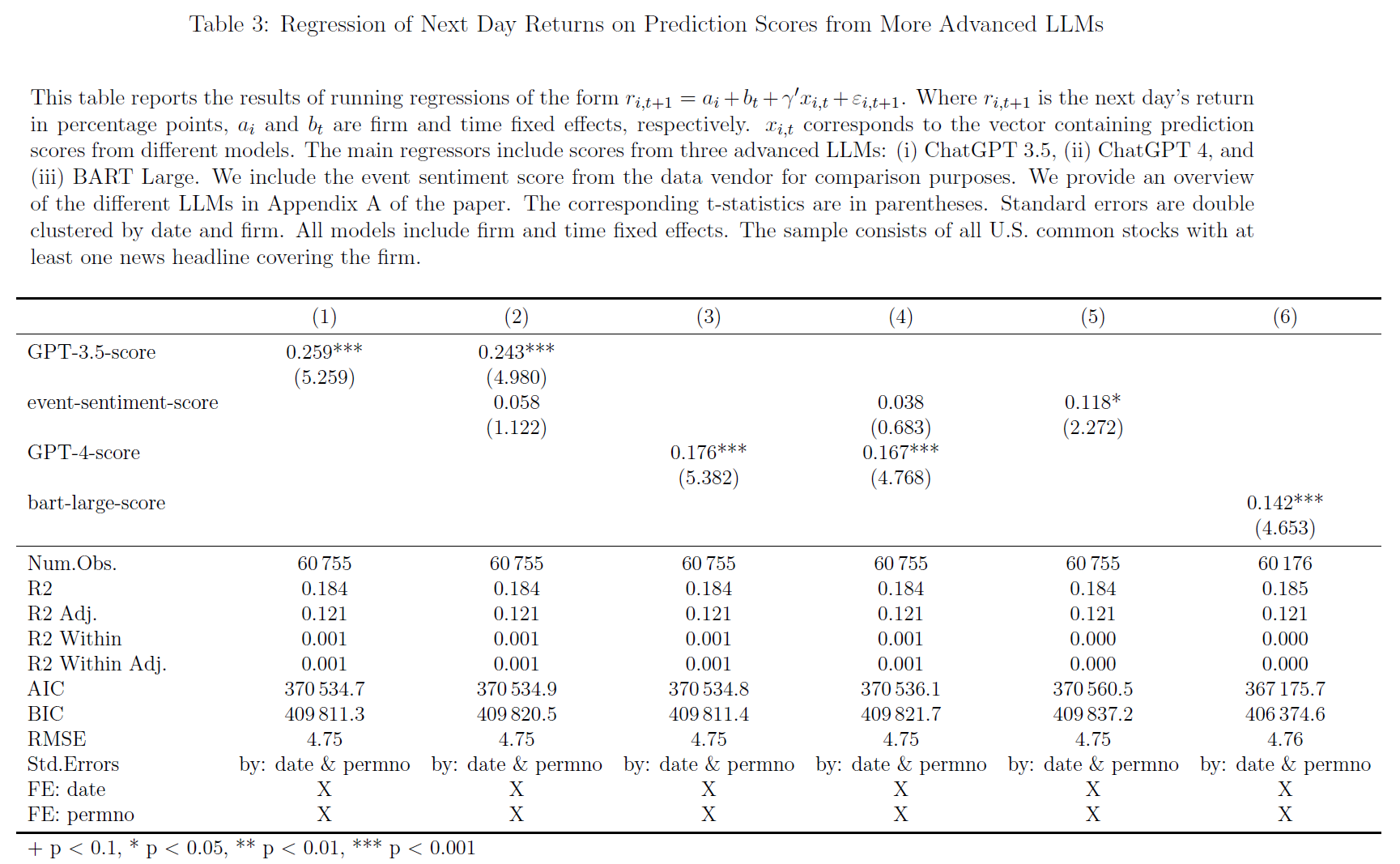
$\color{purple}{表3}$中为股票收益率对更高级LLM得分的回归结果:
首先,统计上与经济上均显著,A switch from a negative (-1) to a positive (1) prediction score is associated with a 51.8 bps increase in next-day stock return. 突显了ChatGPT情绪得分预测股市走势的潜力;
其次,将ChatGPT得分与数据供应商的传统情绪分析方法进行比较,控制ChatGPT情绪得分,检查替代情绪测量的预测能力。控制ChatGPT情绪得分后,数据供应商的情绪得分对每日股市收益的影响减弱,表明ChatGPT在预测股市收益方面优于现有的情绪分析方法;
- 小结论1:ChatGPT预测股市收益优势可归因于其先进的语言理解能力,使其能够捕捉新闻标题中的细微差别和微妙之处,使得该模型能够生成更可靠的情绪得分,从而更好地预测每日股市收益;
- 小结论2:以上证实了ChatGPT情绪得分的预测能力,强调了将LLM纳入投资决策过程的潜在好处,通过优于传统的情绪分析方法,ChatGPT展示了其在提高量化交易策略性能和更准确地了解市场动态方面的价值;
- 最后,分析表明ChatGPT 4情绪得分对每日股市收益也表现出强大且正向的显著预测能力,与$\color{purple}{图1}$和$\color{purple}{表2}$中相一致,$\color{red}{ChatGPT\ 4得分的回归系数低于ChatGPT\ 3.5,但前者更显著}$。控制ChatGPT 4得分后,数据供应商得分不再显著。
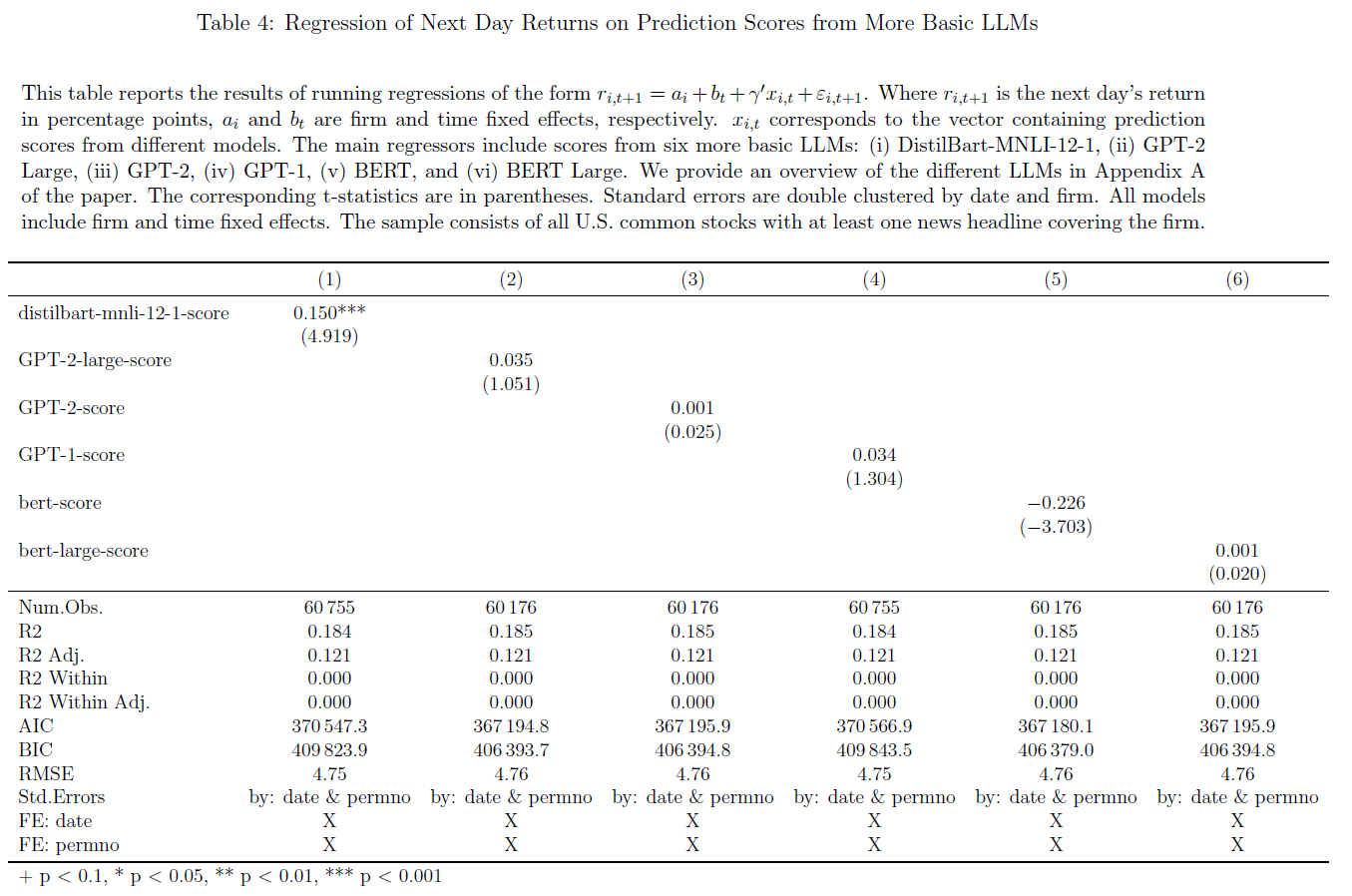
为比较各语言模型的性能,接着使用其他LLM的得分进一步回归
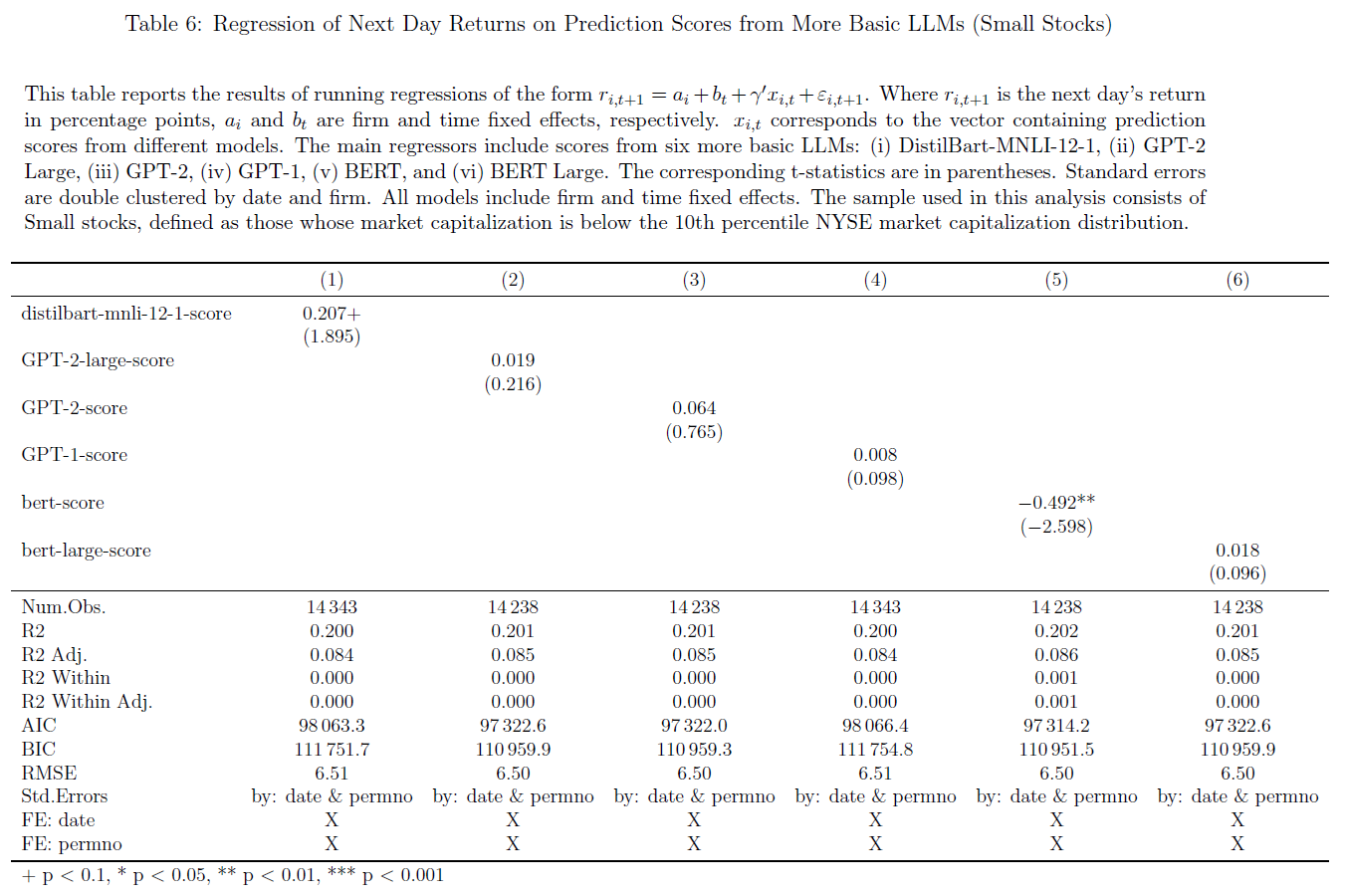
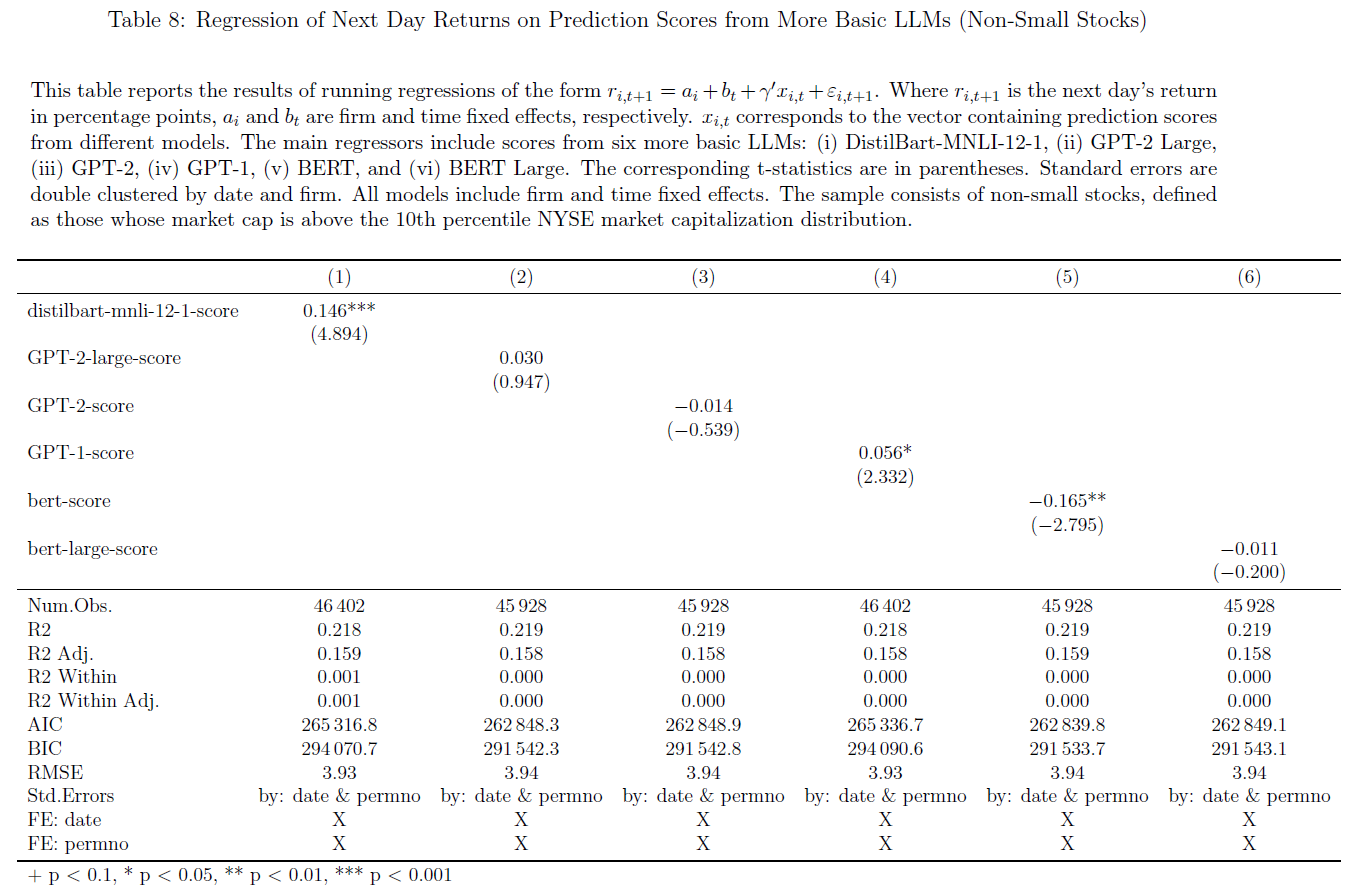
- $\color{purple}{表4}$考虑了六个基本模型:
- DistilBart-MNLI-12-1
- GPT-2 Large
- GPT-2
- GPT-1
- BERT
- BERT Large
- 结果表明:$\color{red}{收益可预测性是更复杂语言模型的新兴能力}$
- BART Large和DistilBart MNLI模型得分具有一定预测能力,但弱于ChatGPT-3.5和ChatGPT-4;
- GPT-1、GPT-2和BERT等基本模型无预测能力,$\color{green}{最复杂模型——ChatGPT\ 4具有最高可预测性}$。
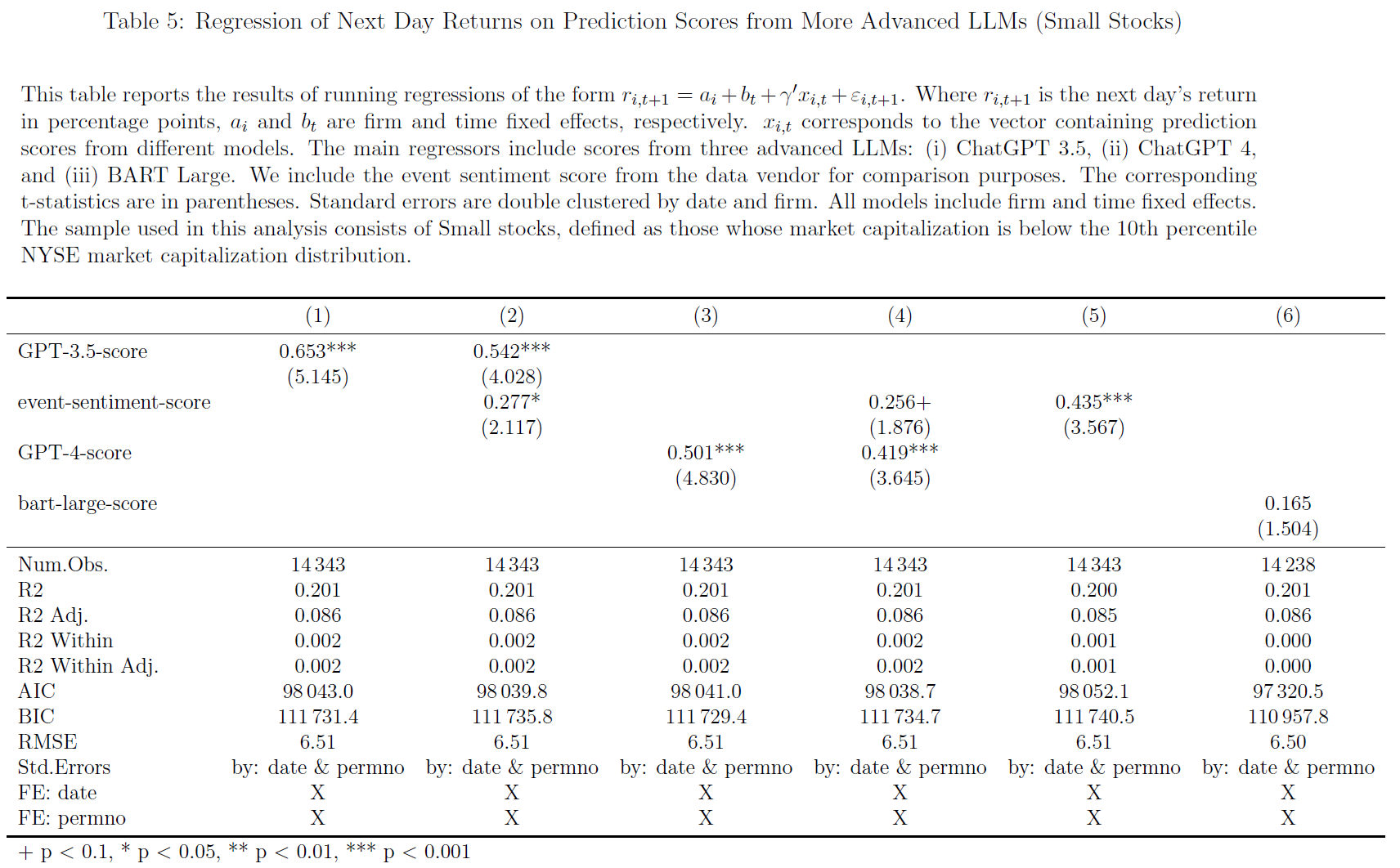
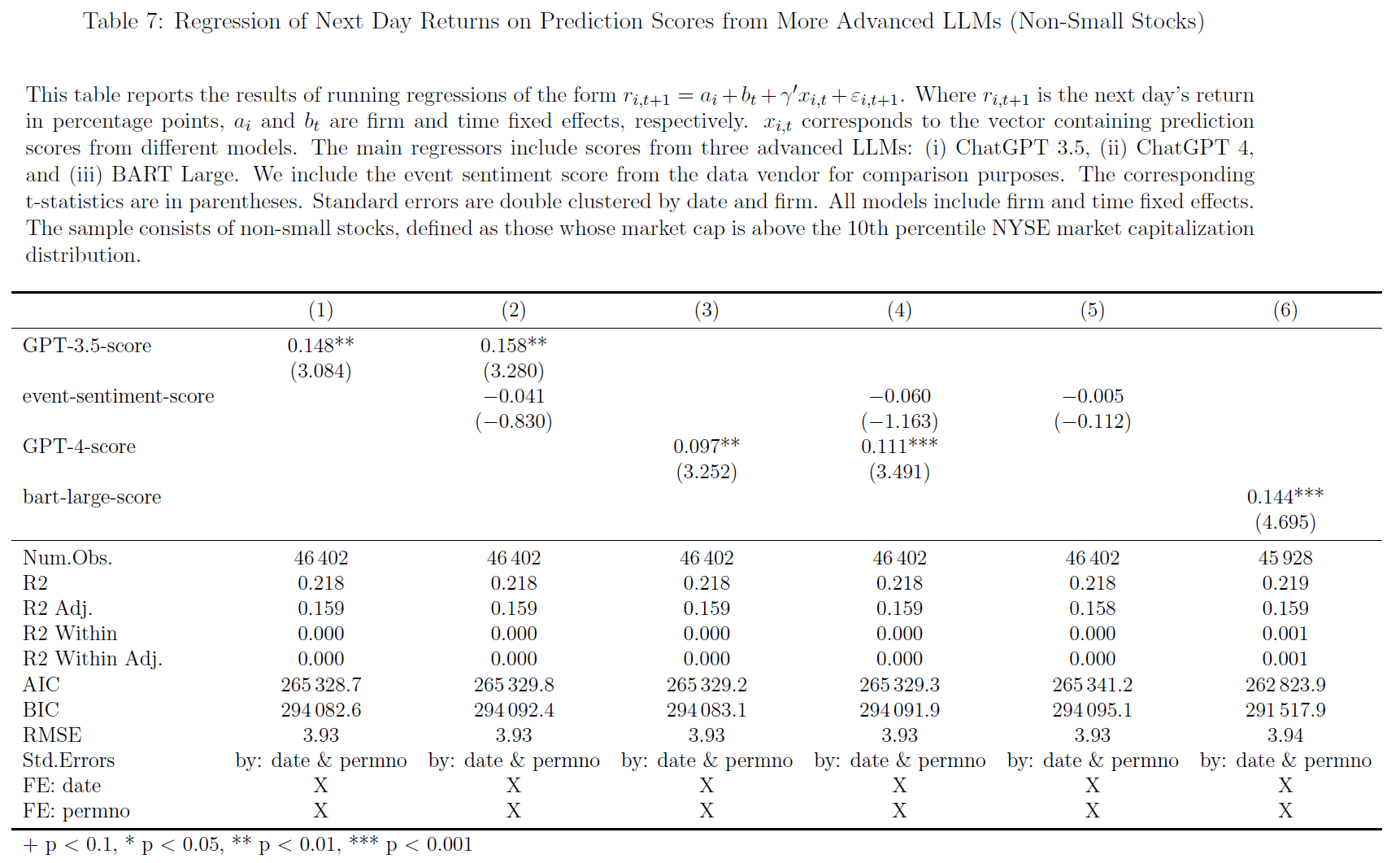
$\color{purple}{表5-8}$验证LLMs于小盘股和大盘股的可预测性:
- ChatGPT得分对小盘股和大盘股均具有预测能力,表明日度频率上$\color{red}{市场对特定公司的新闻反应不足}$,与已有文献观点一致(如post-earnings-announcement drift: $\color{blue}{Bernard\ and\ Thomas,\ 1989}$; Momentum: $\color{blue}{Chan\ et\ al.,\ 1996}$; Investor Inattention and Friday Earnings Announcements: $\color{blue}{DellaVigna\ and\ Pollet,\ 2009}$; limited investor attention: $\color{blue}{Hirshleifer\ et\ al.,\ 2009}$以及underreaction:: $\color{blue}{Jiang\ et\ al.,\ 2021}$;
- 可预测性在小盘股更为明显:
- $\color{purple}{表5}$中ChatGPT 3.5得分预测小盘股回报率(小盘股定义:小于纽约证券交易所市值分布的第10个百分点)的系数是$\color{purple}{表7}$非小型股的四倍多(前者系数0.653,t统计量5.145;后者系数0.148,t统计量3.084),结果与$\color{green}{套利限制在推动这种可预测性方面也发挥着重要作用}$的观点一致;This observation is consistent with the idea that limits-to-arbitrage also play an essential role in driving this predictability.
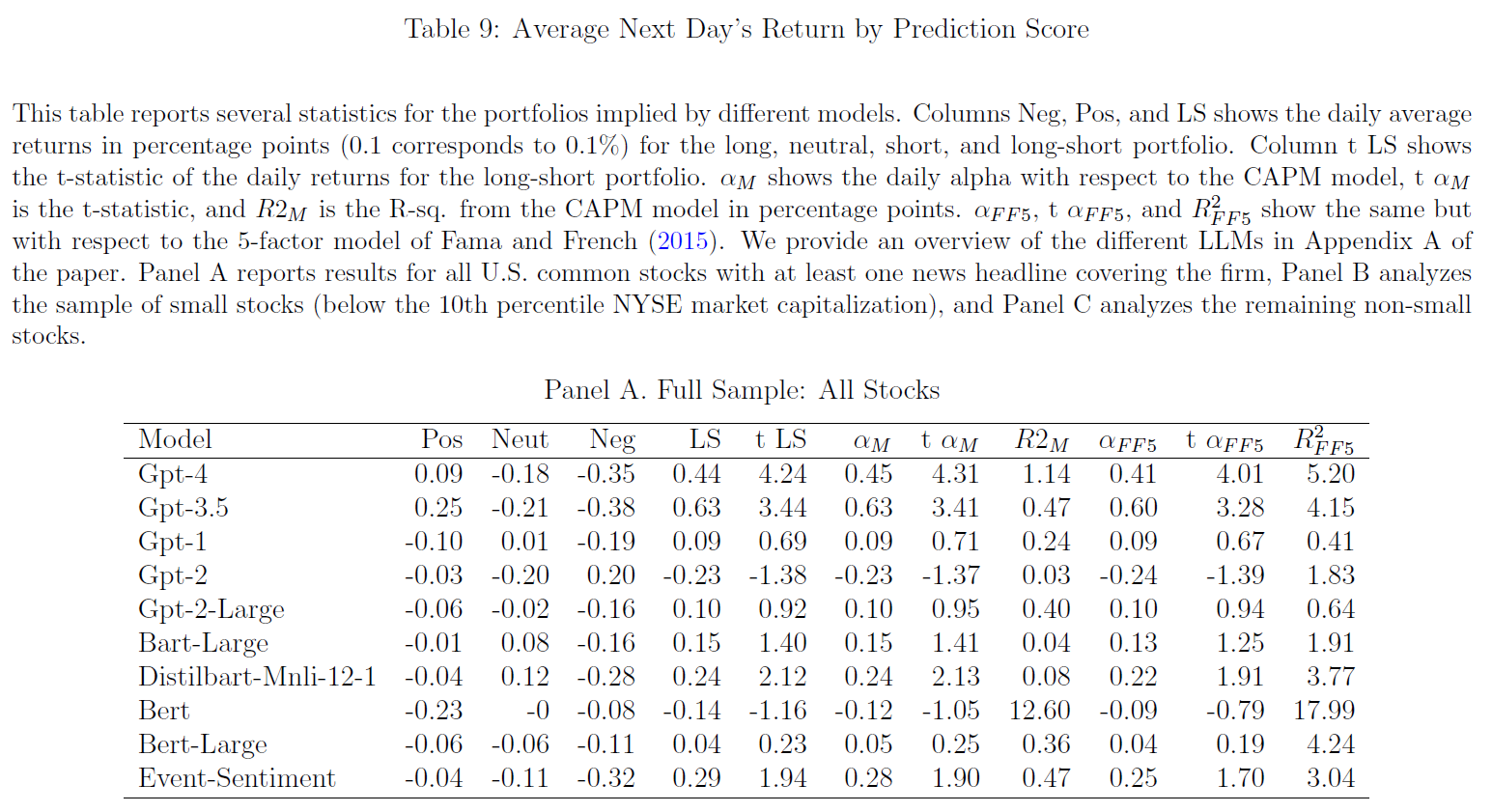
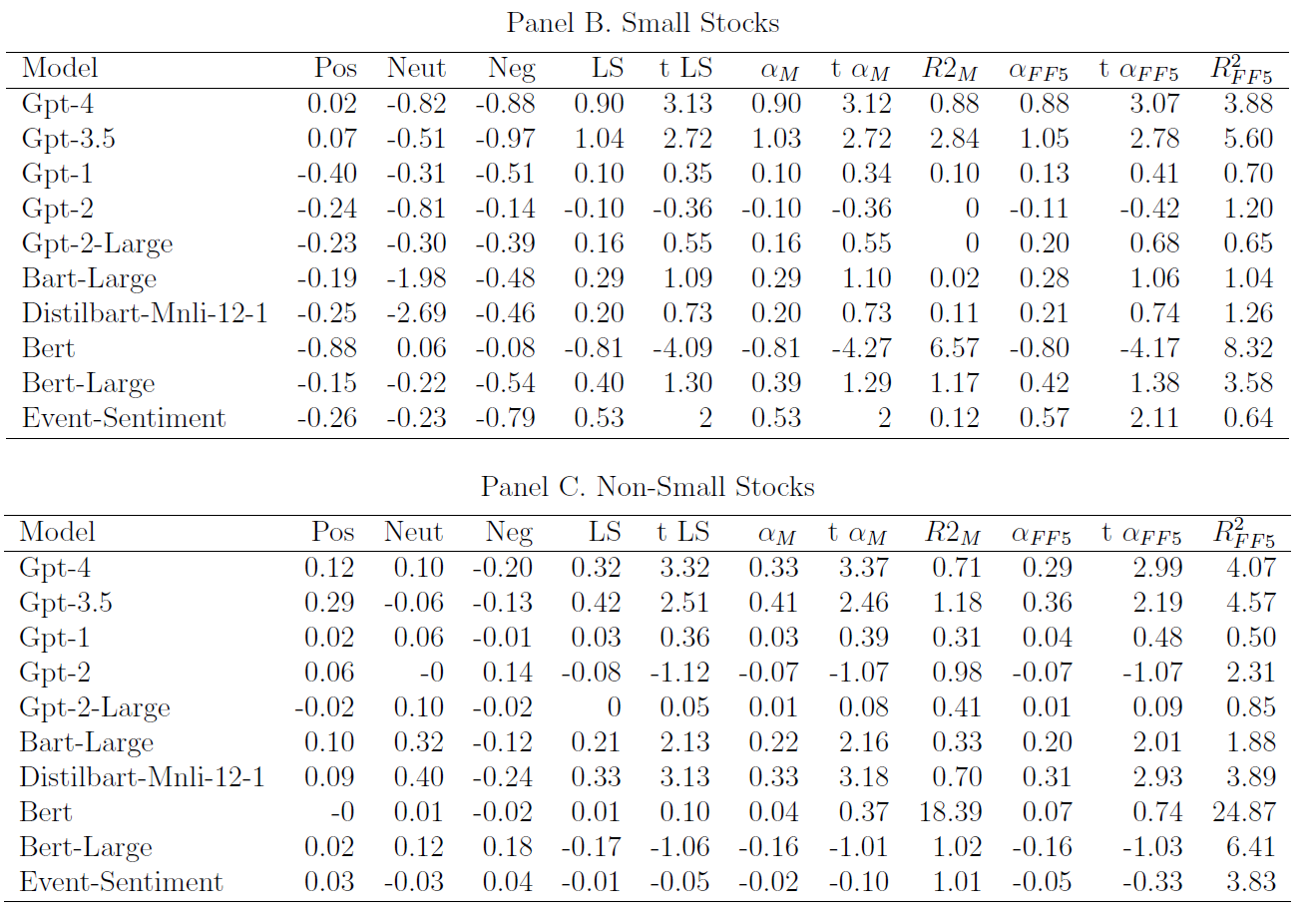
进一步分析不同LLMs预测股市收益,$\color{purple}{表9}$为基于CAPM模型和五因子模型($\color{blue}{Fama\ and\ French,\ 2015}$)的不同模型的平均收益和异常收益:
- $\color{purple}{Panel\ A}$分析普通股全样本,$\color{purple}{Panel\ B}$分析纽约证券交易所小盘股,$\color{purple}{Panel\ C}$分析剩余非小型股;
- 更复杂的模型通常更好:对于GPT-4和GPT-3.5等更先进的模型,平均收益和$α$的幅度及$t$统计量要高得多。
- GPT-4的平均日收益率和五因子$α$分别为44个基点($t$统计量为4.24)和41个基点($t$统计量为4.01),经济和统计上显著;
- 相比之下,GPT-1、GPT-2和BERT等基本模型不会产生显著正收益,同时适用于小盘股和大盘股;
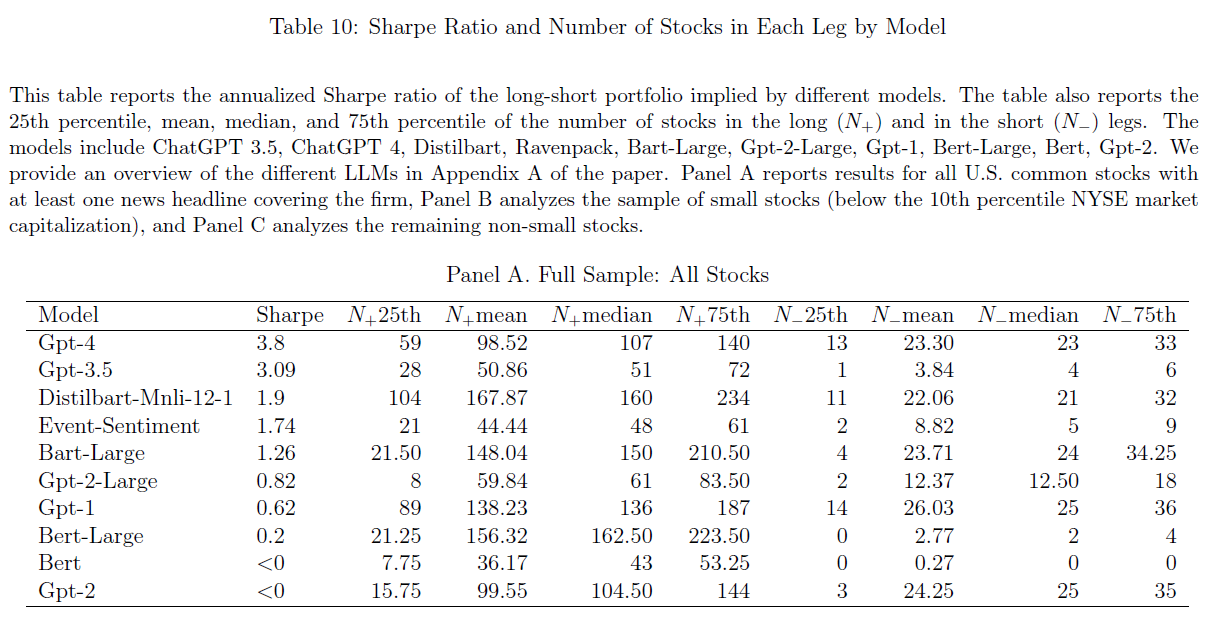
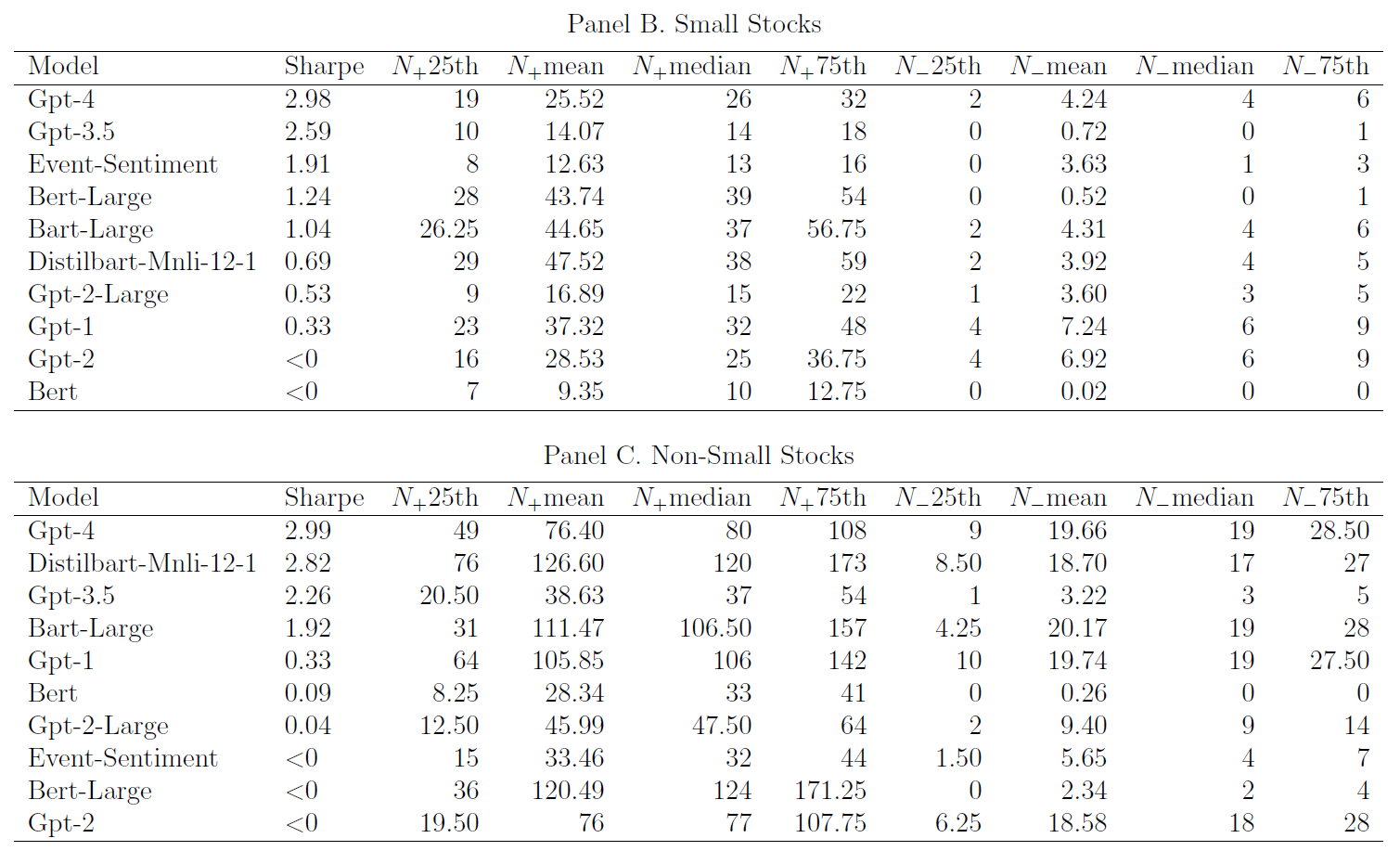
此外,$\color{purple}{表10}$报告了不同模型的夏普比率和股票持仓分布:
- $\color{purple}{Panel\ A}$分析普通股全样本,$\color{purple}{Panel\ B}$分析纽约证券交易所小盘股,$\color{purple}{Panel\ C}$分析剩余非小型股;
- GPT-3.5“多空”策略产生更高的平均收益率和$α$,$\color{green}{持有头寸不够多样化}$
- $\color{purple}{Panel\ A}$GPT-3.5“空头”和“多头”策略的平均股票数量分别为3.8只和50.9只;
- GPT-4策略相应数字分别为23.3和98.5,均明显高于GPT-3.5策略(“空头”更甚),两个分支投资组合更加多样化,夏普比率更高为3.8,而GPT-3.5的夏普比率为3.1;
- $\color{green}{更复杂的模型具有更高的夏普比}$;
- $\color{green}{复杂模型在非小盘股仍然具有较高的夏普比率}$(例如$\color{purple}{Panel\ C}$去除小盘股后,GPT-4的夏普比率也高达2.99;
- $\color{red}{模型理解自然语言的总体能力似乎与准确预测回报的能力呈正相关}$。
Interpretability
Evaluating ChatGPT’s Reasoning Capabilities
传统的金融机器学习模型主要关注预测,往往缺乏可解释性。[Traditional machine learning models in finance primarily focus on prediction, often lacking interpretability.]
In contrast, large language models (LLMs) like ChatGPT offer predictions and associated explanations in natural language. This distinctive feature provides a deeper insight into the rationale behind each prediction, a capability largely absent in conventional models. Motivated by this unique attribute, we devise a novel framework to harness these qualitative insights for enhanced predictive accuracy.
相较于$\color{red}{提供有限透明度的传统定量模型}$,ChatGPT以通俗易懂的语言$\color{red}{呈现文本推理}$,增加了丰富的$\color{red}{定性信息层}$。[Unlike traditional quantitative models offering limited transparency, ChatGPT presents con-textual reasoning in plain language, adding a rich layer of qualitative information.]
假设:
1 | 充满细微细节的解释可能有助于收益的可预测性 |
- 初始阶段集中完善ChatGPT-4的文本解释,提取得分的原始解释文本,将定性陈述与分数分离。
- 剔除“是”、“否”和“未知”等明确的情绪指标,指标会降低情绪的定性深度;
- 主要关注模型基本原理的本质,删除预测得分,可为彻底分析奠定基础;
- 目的将ChatGPT的解释转化为更可量化的格式:
- 剔除中性分数,对积极或消极的原因解释进行细分;
- 分割后可以更集中分析,支持我们的假设(即如果涉及乐观或悲观的预测,解释的正确性不同)。
- 接下来,将定性数据转换为结构化的定量数据进行回归分析:
- 采用词频-逆文档频率(TF-IDF)技术;
- $\color{red}{独特术语}$极其重要性,因为其突出了可能表达强烈市场情绪和潜在股票走势的词语。
$\color{purple}{图4}$、$\color{purple}{图5}$、$\color{purple}{图6}$和$\color{purple}{图7}$分别展示了所有、积极、消极和中性解释TF-IDF总分最高的单词。
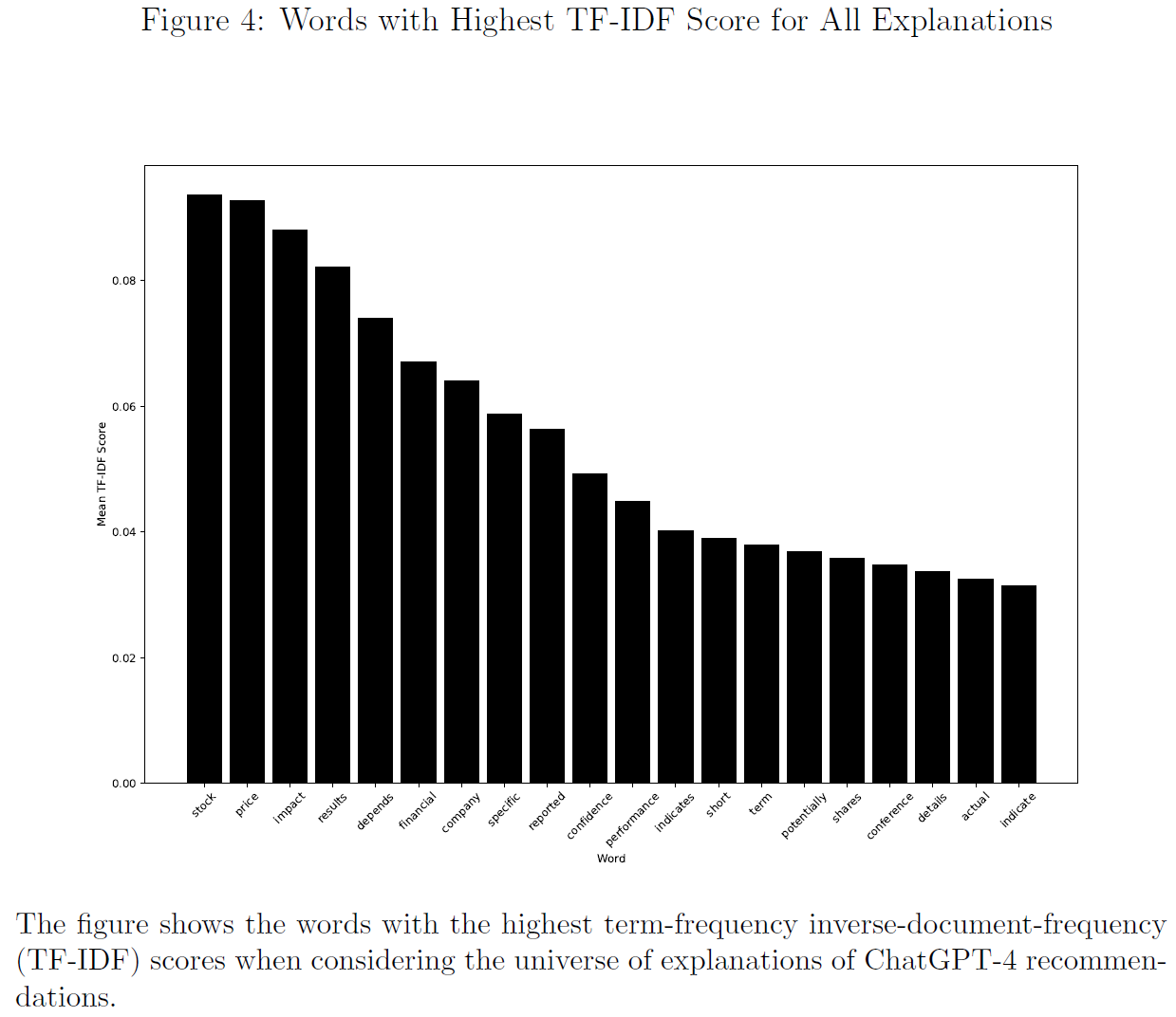
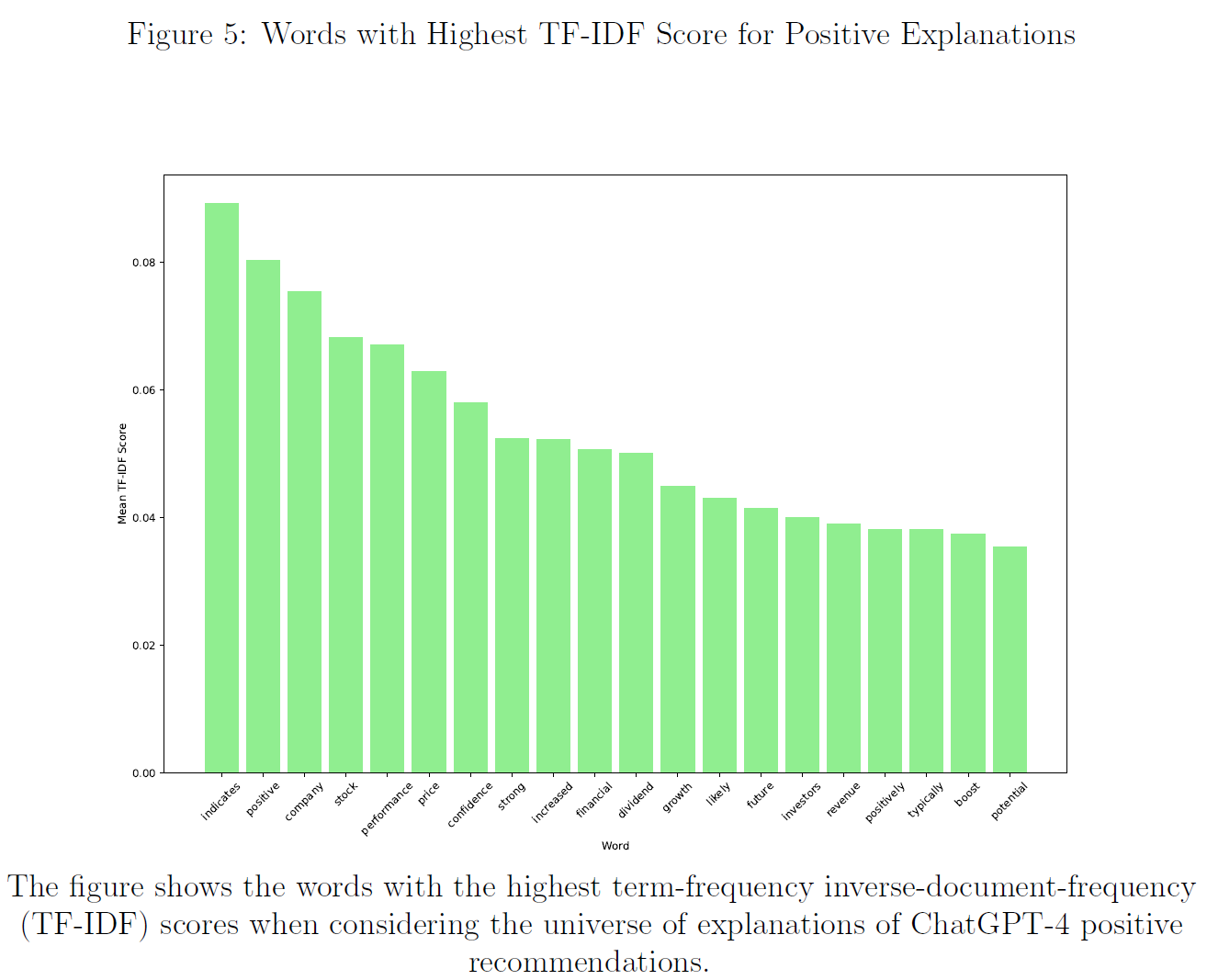
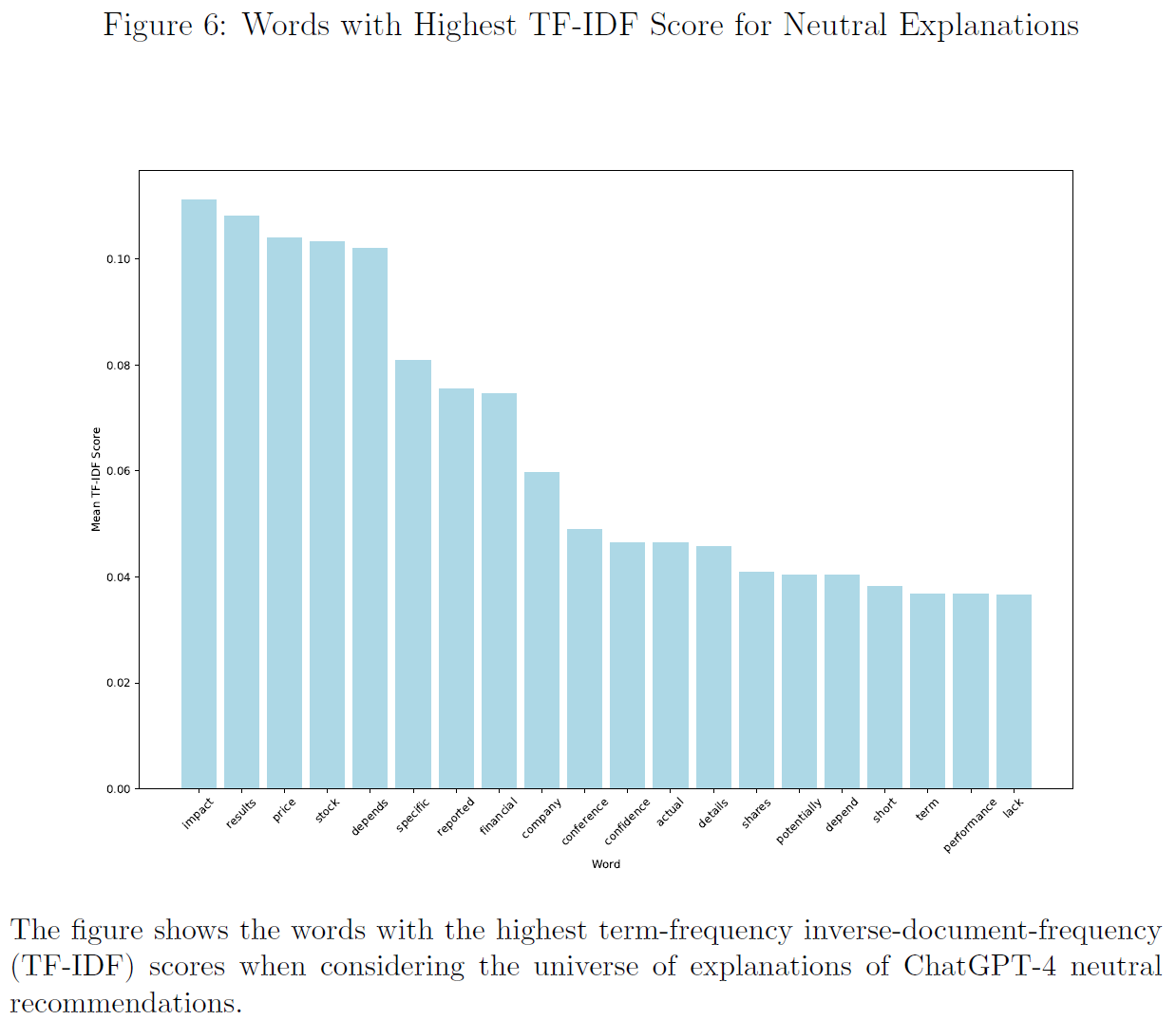
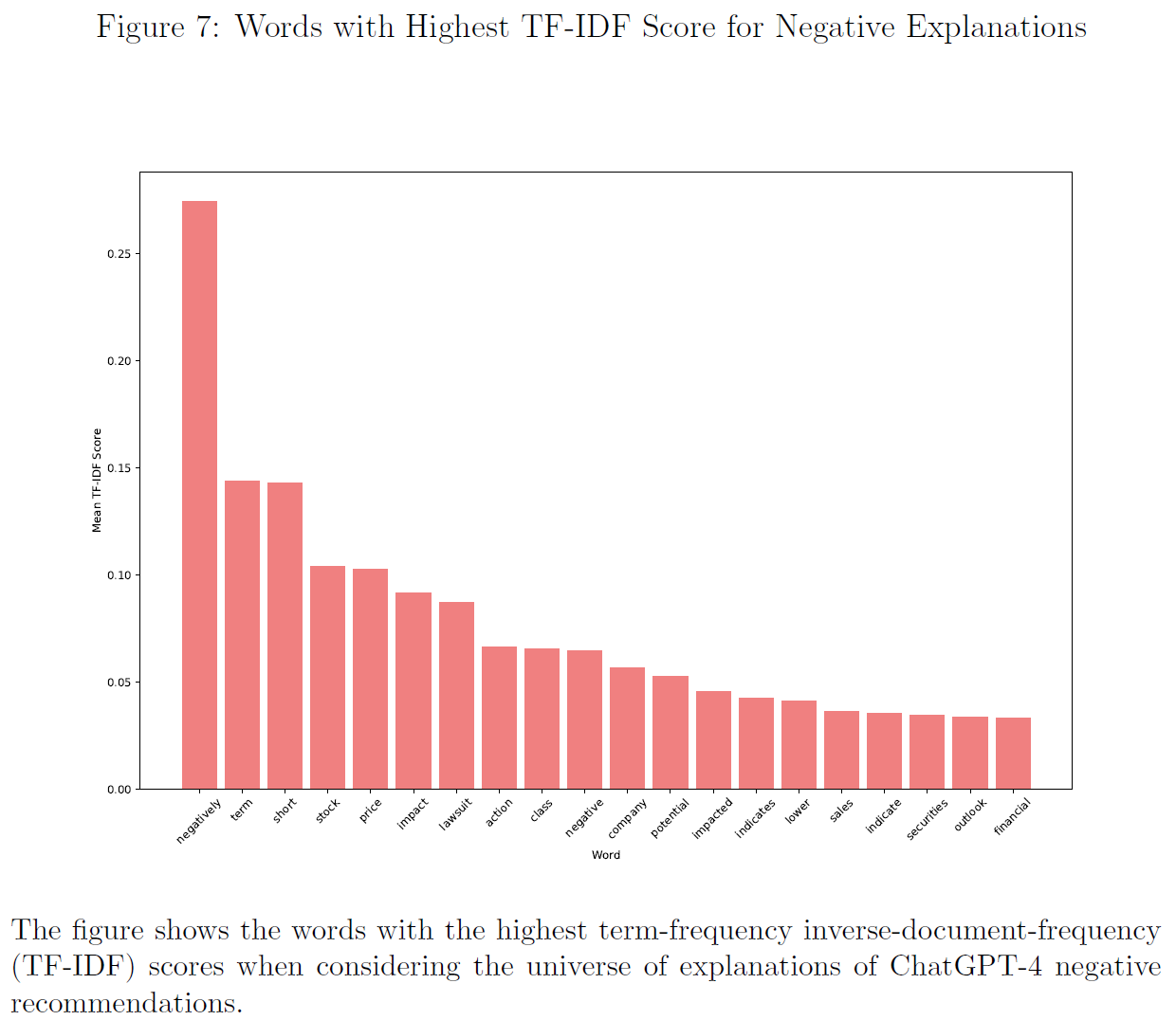
然而,此方法无法区分解释的正确与否,因此使用有监督方法表征最能预测给定解释是否与结果正确相关的单词。
[However, this method does not allow distinguishing between correct and incorrect explanations. To do so, we use a supervised approach to characterize the words that best predict if a given answer relates correctly to the outcome.]
将文本解释转换为结构化数据后,使用逻辑回归模型(选择逻辑回归是由于二元结果变量:股价是否朝着ChatGPT预测的方向移动),用以核实定性解释的预测能力;
通过训练积极和消极新闻解释的不同模型,旨在捕捉乐观和悲观理论如何影响股价动态的微妙变化,以此提供对市场情绪驱动行为更全面的看法;
如何理解个体特征的意义和影响至关重要:
- 首先提取逻辑回归模型中系数最高和最低的项(这种方法提供了正系数和负系数),以识别对解释是否正确影响最大的单词;
- 根据每组单词对预测准确性的影响被分为“正确”和“不正确”,可揭示ChatGPT所依赖的词典,并说明某些术语如何与特定思想更加一致;
虽然单个单词很有趣,但脱离上下文,难以理解其全部影响:
- 为了更深入地研究有影响力单词的上下文语境,接着确定伴随目标单词的单词;
- 通过为平均TF-IDF设置阈值百分位数过滤不太重要的单词,确保附带的单词列表既相关又有影响力;
- 这样不仅孤立地看待单词,而且了解它们在更广泛的背景下的意义,从而揭示支撑股市预测的复杂关系网;
$\color{purple}{表11}$报告了ChatGPT-4关于几个主题的积极解释结果:
- 首先,当其推理与内部人士的股票购买(stock purchases by insiders)有关时,该模型可以令人满意地预测;
- 其次,当其解释与盈利指导(earnings guidance)相关时,该模型预测准确;
- 第三,该模型在与每股收益(earnings per share)或市场份额(market share)相关的主题上表现良好;
- 最后,当主题与股息(dividends)相关时,该模型预测准确;
- 相反,当模型的推理涉及伙伴关系(partnerships)或新的发展(new developments)时,该模型预测较差;
- 用利润(profits)、销售额(sales)和盈利能力(profitability)证明解释的合理性时预测较差,三者产生负面影响的一个潜在原因可能是:新闻发布时,ChatGPT只接收了新闻标题,而没有收到关于公司利润或销售额的市场预期。对于盈利发布等预定事件,将市场预期作为基准来梳理推动市场的因素至关重要;

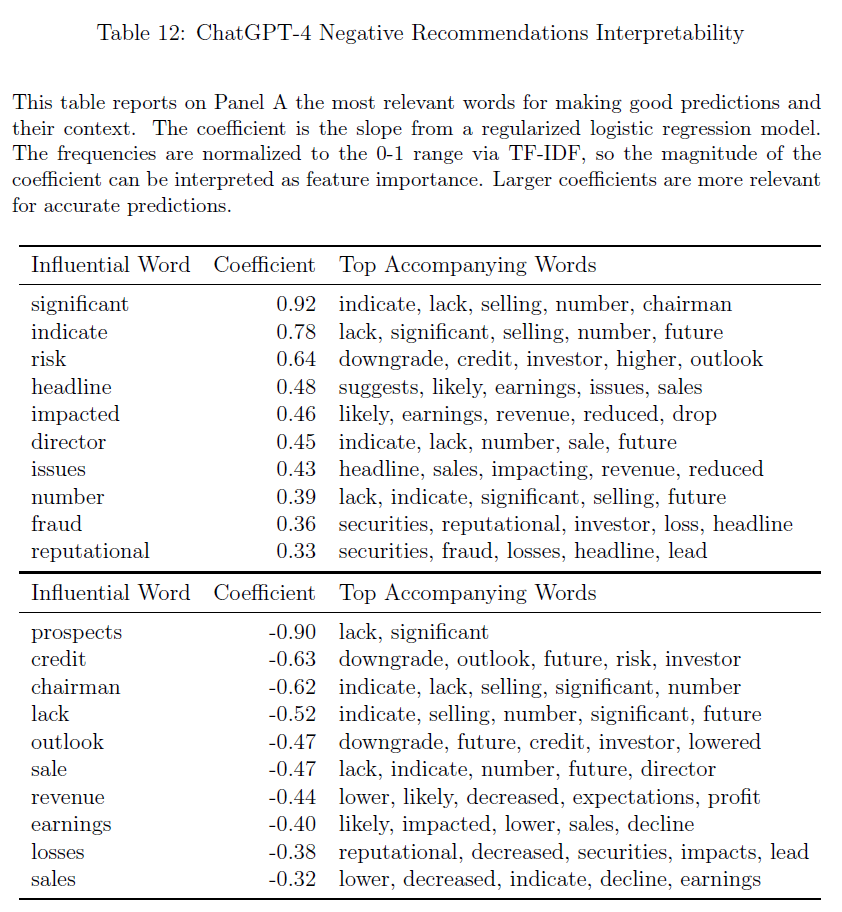
$\color{purple}{表11}$展示了ChatGPT-4关于几个主题的消极解释结果:
- 首先,当其推理与降级风险或与信贷相关的风险相关时,该模型预测准确;
- 其次,当主题与对收益或收入产生负面影响的因素相关时,该模型预测准确;
- 第三,该模型准确预测了主题何时与欺诈或声誉损害有关;
- 最后,当该模型的解释涉及董事出售证券时,该模型预测准确;
- 相反,当模型的推理与前景或展望有关时,该模型预测较差;
- 对利润、销售额和盈利能力进行解释时,该模型预测较差;
Conclusion
本研究使用新闻标题的情绪分析研究ChatGPT和其他大语言模型在预测股市回报方面的潜力,新发现如下:
- 首先,新闻标题的ChatGPT得分可以预测后续每日股票收益,可预测性==优于领先数据供应商的传统情绪分析方法==;
- 其次,GPT-1、GPT-2和BERT等更基本的LLMs无法准确预测收益,基于ChatGPT-4的策略提供了最高的夏普比率,==表明回报可预测性是复杂语言模型的一种新兴能力==。
- 第三,ChatGPT得分的可预测性同时出现在小盘股和大盘股中,==表明市场对公司新闻的反应不足==;
- 第四,==可预测性在小盘股和有坏消息的股票中更强==,与套利限制一致也起着重要作用;
- 最后,==提出了一种新的方法来评估和理解模型的推理能力==;
- 通过展示LLMs在金融经济学中的价值,为越来越多的关于人工智能和自然语言处理在该领域应用的文献做出了贡献;
本研究对未来的研究启示如下:
- 首先,强调继续探索和开发专门为金融业量身定制的LLM的重要性,随着人工智能驱动的金融的发展,可以设计更复杂的模型来提高金融决策过程的准确性和效率;
- 其次,==未来的研究可更集中理解LLMs获得预测能力的机制上==,通过确定促成ChatGPT成功预测股市收益等模型的因素,研究人员可以制定更有针对性的策略来改进这些模型,并最大限度地提高其在金融中的效用;
- 此外,随着LLMs在金融行业越来越普遍,有必要调查==其对市场动态的潜在影响==,包括价格形成、信息传播和市场稳定性。未来的研究可以探索LLM在==塑造市场行为中的作用==及其对金融系统的潜在积极和消极影响;
- 最后,未来的研究可以探索==LLMs与其他机器学习技术和定量模型的集成==,以创建结合不同方法优势的混合系统。通过利用各种方法的互补能力,研究人员可以进一步增强人工智能驱动模型在金融生态经济学中的预测能力;
简言之,本研究证明了ChatGPT在预测股市收益方面的价值,为未来研究LLMs在金融行业的应用和影响铺平了道路。随着人工智能驱动的金融领域的不断扩展,从这项研究中收集到的见解有助于指导开发更准确、高效和可信的模型,以提高金融决策过程的效率。
参考文献
- Tetlock, P. C. (2007). Giving content to investor sentiment: The role of media in the stock market. The Journal of Finance, 62(3), 1139-1168.
- Tetlock, P. C., Saar‐Tsechansky, M., & Macskassy, S. (2008). More than words: Quantifying language to measure firms’ fundamentals. The journal of finance, 63(3), 1437-1467.
- Tetlock, P. C. (2011). All the news that’s fit to reprint: Do investors react to stale information?. The Review of Financial Studies, 24(5), 1481-1512.
- Fedyk, A., & Hodson, J. (2023). When can the market identify old news?. Journal of Financial Economics, 149(1), 92-113.
- Jiang, H., Li, S. Z., & Wang, H. (2021). Pervasive underreaction: Evidence from high-frequency data. Journal of Financial Economics, 141(2), 573-599.
- Bernard, V. L., & Thomas, J. K. (1989). Post-earnings-announcement drift: delayed price response or risk premium?. Journal of Accounting research, 27, 1-36.
- Chan, L. K., Jegadeesh, N., & Lakonishok, J. (1996). Momentum strategies. The Journal of Finance, 51(5), 1681-1713.
- DellaVigna, S., & Pollet, J. M. (2009). Investor inattention and Friday earnings announcements. The Journal of Finance, 64(2), 709-749.
- Hirshleifer, D., Lim, S. S., & Teoh, S. H. (2009). Driven to distraction: Extraneous events and underreaction to earnings news. The Journal of Finance, 64(5), 2289-2325.
- Jiang, H., Li, S. Z., & Wang, H. (2021). Pervasive underreaction: Evidence from high-frequency data. Journal of Financial Economics, 141(2), 573-599.
- Fama, E. F., & French, K. R. (2015). A five-factor asset pricing model. Journal of Financial Economics, 116(1), 1-22.
 微信
微信 支付宝
支付宝




