
Tech | Stanford and UW Researchers Train a Powerful AI Reasoning Model for Under $50

2025年1月31日,斯坦福大学和华盛顿大学的AI研究团队发布了一篇引发行业轰动的研究论文,他们成功以不到50美元的训练成本打造了一个高性能AI推理模型——s1,其在数学推理和编程能力测试中的表现,足以媲美当前最前沿的推理模型,如 OpenAI 的 o1 和 DeepSeek 的 R1!
更令人瞩目的是,s1 已在 GitHub 上开源,不仅提供了完整的训练代码和数据,还为学术界、开源社区乃至 AI 初创公司提供了低成本构建高性能 AI 模型的新范式。这不仅是 AI 研究的一次突破,更可能引发推理模型开发的“平民化革命”。
这一成果表明,先进的推理能力不再是科技巨头的专属,通过高效的训练方法与创新的模型优化,即便是资源有限的研究团队,也能在 AI 竞赛中占据一席之地。s1 的成功,让人不禁思考:未来的 AI 发展,是否还依赖巨额算力投入,还是会向更加开放、普惠的方向演进?
工作论文:
Github仓库:
技术突破:蒸馏与微调,低成本复刻最前沿推理能力
s1 模型的研究团队采用了创新性的“蒸馏”技术,从 Google 的推理模型——Gemini 2.0 Flash Thinking Experimental 中提取推理能力,并通过精细化的监督微调(SFT) 使其适应新的任务环境。相比于传统的大规模预训练+强化学习方法,这种技术路径显著降低了计算成本,同时保留了强大的逻辑推理能力。
更令人惊讶的是,整个训练过程仅耗时不到 30 分钟,并且在 16 台 Nvidia H100 GPU 上完成,这意味着在极短的时间内,研究团队成功构建了一个能够媲美 OpenAI o1 和 DeepSeek R1 的推理模型。这一成果不仅证明了蒸馏技术的可行性,也展示了如何以极低的成本实现高性能 AI 推理,为学术界和开源社区提供了全新的研究范式。
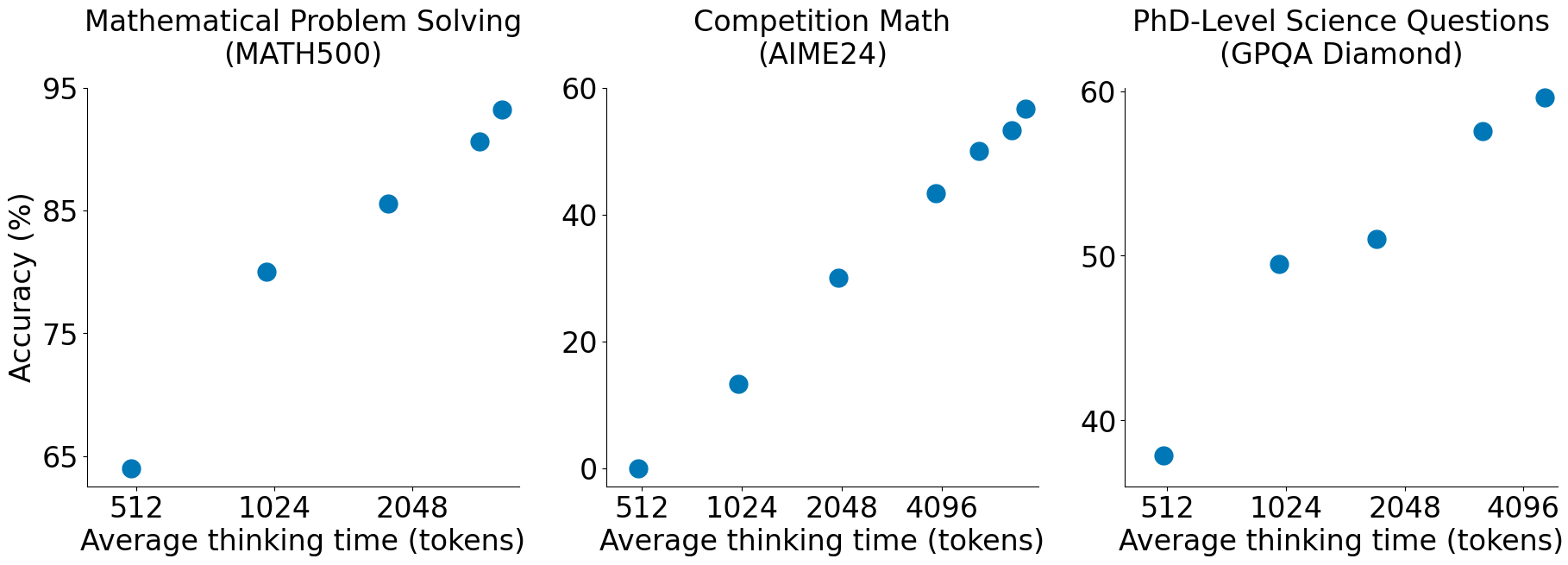
此外,研究人员还采用了巧妙的优化策略,例如在推理过程中引入“wait”机制,让模型在回答问题前“思考”更久,以提高答案的准确性。这种方法突破了传统推理模型的速度-精度权衡,使得 s1 在多个 AI 基准测试中表现优异。
这一突破性进展不仅让低成本 AI 训练成为可能,也引发了关于 AI 训练范式转变的深远讨论——当蒸馏和微调技术逐渐成熟,是否意味着算力和数据不再是 AI 进步的唯一壁垒? 未来,依靠更高效的训练方法和优化策略,是否能催生一波“轻量级高性能 AI” 的浪潮?
低成本的“AI革命”:AI的护城河正在消失?
与传统的高成本、大规模训练方法不同,s1 的训练成本极为低廉。研究人员仅使用1000 个精心挑选的问题构建训练数据,并结合监督微调(SFT) 技术,使得这一推理模型具备了媲美最前沿 AI 推理系统的能力。整个训练过程在 16 台 Nvidia H100 GPU 上仅运行了不到 30 分钟,成本不足 50 美元,这一突破无疑挑战了 AI 领域“算力决定一切”的传统认知。
相较于 DeepSeek 依靠数百万美元的算力进行强化学习训练,s1 的低成本策略不仅打破了“资金壁垒”,更让 AI 研究从资源密集型产业迈向更开放、更可复制的阶段。这种模式让更多学术研究机构、中小企业乃至个人开发者都能低成本进入 AI 竞赛,从而加速 AI 技术的普及化。
然而,这一趋势也引发了行业对 AI “商品化” 的深刻讨论。如果一个价值数百万美元的大模型可以通过低成本蒸馏技术被高效复刻,AI 产业的“护城河”究竟在哪里? 未来,AI 是否会像云计算或开源软件一样,从封闭式竞争走向更加模块化、低成本的开放生态?或者,科技巨头是否会通过数据垄断、模型封闭化等方式,进一步巩固自身的领先地位?
s1 的成功无疑给 AI 产业带来了新的思考。是资本堆砌的 AI 时代仍将主导未来,还是更加去中心化、普惠化的 AI 体系将逐渐崛起? 这一低成本革命,或许才刚刚开始。
创新背后的挑战与思考
尽管s1的创新令人振奋,但也引发了大AI实验室的关注。OpenAI 近期指控 DeepSeek 滥用其 API 进行模型蒸馏,尽管这一指控与 s1 无关,但AI行业对蒸馏技术的争议也因此升温。DeepSeek的做法和s1的技术路径完全不同,但由于两者都涉及到AI推理模型的蒸馏,OpenAI的指控给整个AI领域的模型蒸馏技术带来了更大的关注。

Google 明确禁止对其 Gemini 2.0 Flash Thinking Experimental 进行逆向工程,以开发与其自家 AI 竞争的产品。尽管 s1 研究团队通过 API 获取数据,并未涉及逆向工程,但这一规定仍引发关于 AI 训练数据边界的讨论。
AI的未来:依赖巨额投资,还是迈向普惠智能?
尽管蒸馏技术证明了低成本也能复制强大推理能力,但 AI 领域的核心竞争仍然掌握在算力、数据和算法优化等关键要素之上。Meta、Google、Microsoft 等科技巨头计划在 2025 年投入数千亿美元用于 AI 基础设施建设,进一步优化大模型的训练效率,推动更复杂、更智能的 AI 解决方案。这种资本密集型的投入仍然是当前 AI 产业创新的主流路径,而算力资源的垄断也让这些企业在 AI 竞争中保持着天然优势。
然而,s1 的成功正在改变这一传统认知。它表明,即便没有大规模资金支持,依靠更优化的训练方法、合理的数据选择和算法改进,同样可以取得接近最前沿模型的推理能力。这一突破可能为学术研究、开源社区和中小型 AI 创企提供新的发展方向,让 AI 技术的应用不再局限于少数资本雄厚的企业,而是逐步迈向去中心化、开放共享的创新模式。
但与此同时,低成本 AI 模型的发展也带来了新的挑战——模型知识产权如何界定?训练数据是否合规?算力成本降低是否会导致 AI 滥用问题? 这些问题将在未来几年成为业界关注的焦点。科技巨头的巨额投资仍然在引领 AI 的前沿突破,而开源社区和学术界的技术创新则在推动 AI 的平民化和普惠化。未来,AI 产业可能会形成高投入大模型与低成本开源模型并存的双轨发展格局,既有资本驱动的超大规模 AI 竞赛,也有面向大众的轻量级 AI 生态。
AI 的未来不只是巨头的游戏,更可能是一场由全球研究者共同推动的技术变革。
结语
s1 的成功不仅标志着 AI 推理模型的一次突破,更揭示了低成本 AI 研究的巨大潜力。过去,高性能 AI 推理模型的训练往往需要数百万美元的算力支出,使得这一领域长期被大型科技公司主导。然而,s1 研究团队证明,借助巧妙的算法优化、有效的数据选择和高效的训练策略,即便是在资源受限的情况下,也能复刻甚至接近最前沿的推理能力。
这一研究不仅为学术界和开源社区提供了重要的借鉴,也可能为 AI 产业带来深远影响。随着模型蒸馏和监督微调(SFT)等技术的成熟,未来或许会涌现更多类似 s1 的开源推理模型,推动 AI 技术的民主化、平民化和普惠化。这意味着,不仅是资金雄厚的大型科技公司,高校、研究机构乃至个人开发者都有机会在 AI 推理领域取得突破,从而进一步加速 AI 研究和应用的创新步伐。
然而,低成本模型的兴起也引发了一系列挑战。AI 技术的知识产权、数据使用边界、算法安全性等问题正变得愈发突出。s1 的问世让人重新思考,如果昂贵的专有模型能够被低成本复刻,AI 产业的商业模式是否会发生根本性变革? 大公司依靠海量数据和算力建立的护城河是否依然坚固?监管机构是否会介入 AI 训练数据的使用?这些问题仍然有待时间和市场的进一步检验。
未来,s1 的成功或许只是一个开端。当计算资源的获取成本持续下降,当算法优化能力不断提升,“高性能 AI ≠ 高昂成本” 可能成为行业共识。在这一变革浪潮中,开源社区、学术机构和创业团队或将迎来前所未有的创新机遇,而 AI 产业的竞争格局也可能因这一波低成本革命而被重新定义。
参考文献
 微信
微信 支付宝
支付宝

