
Draft | DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
在大语言模型(LLM)迅速发展的浪潮中,DeepSeek-AI 团队提出了一项突破性研究——DeepSeek-R1,该模型利用强化学习(RL)显著提升了 AI 在数学、编程、科学推理等任务中的推理能力,并在多个权威基准测试中取得了领先成绩。
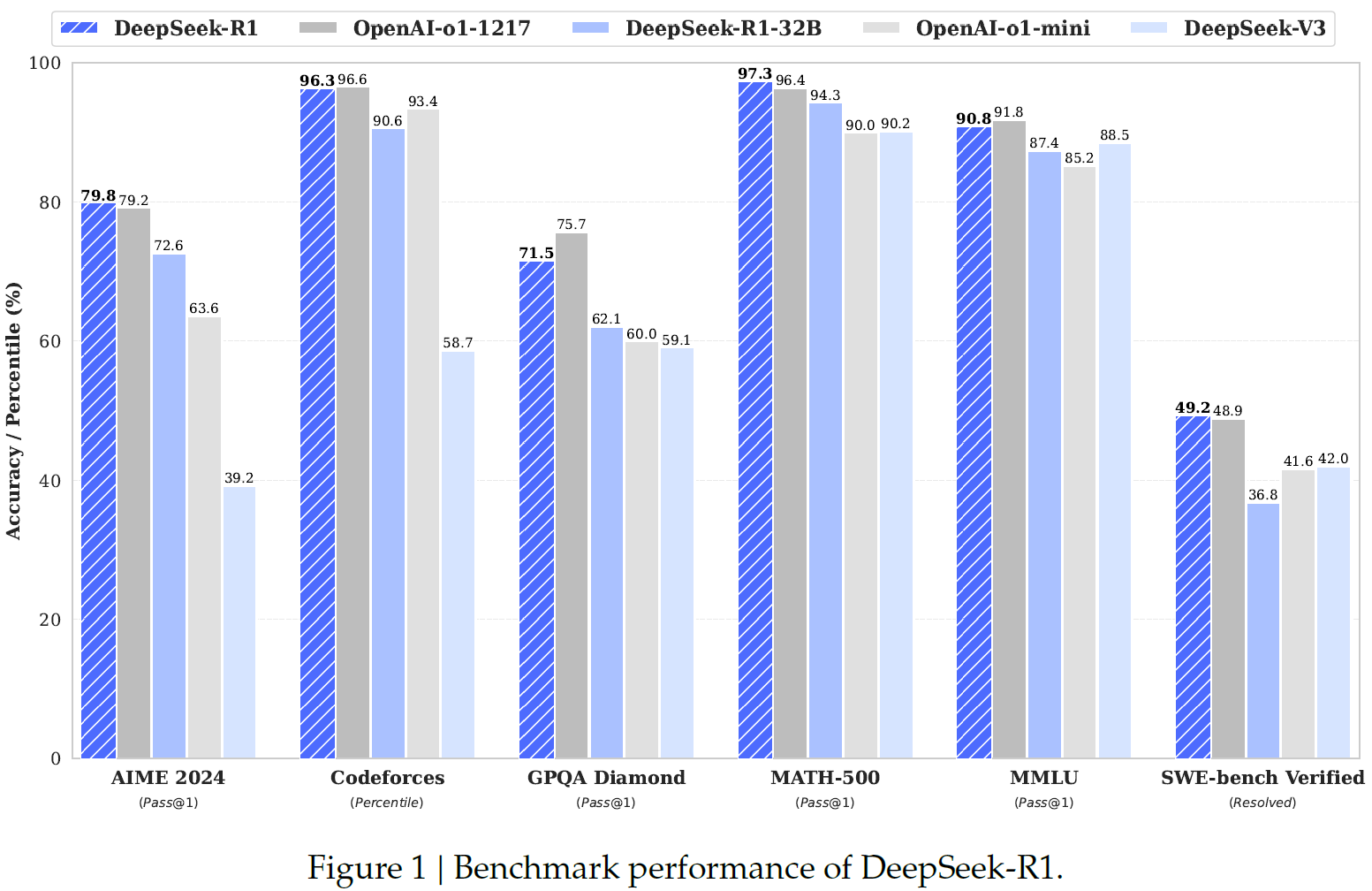
论文中,研究团队首先提出了 DeepSeek-R1-Zero,一个完全依靠强化学习训练的大语言模型,展示了卓越的推理能力。然而,该模型也暴露出可读性较差、语言混杂等问题。为此,团队进一步优化,推出 DeepSeek-R1,通过引入冷启动数据和多阶段训练,大幅提升了推理质量,并在推理任务上达到了 OpenAI o1-1217 的水平。
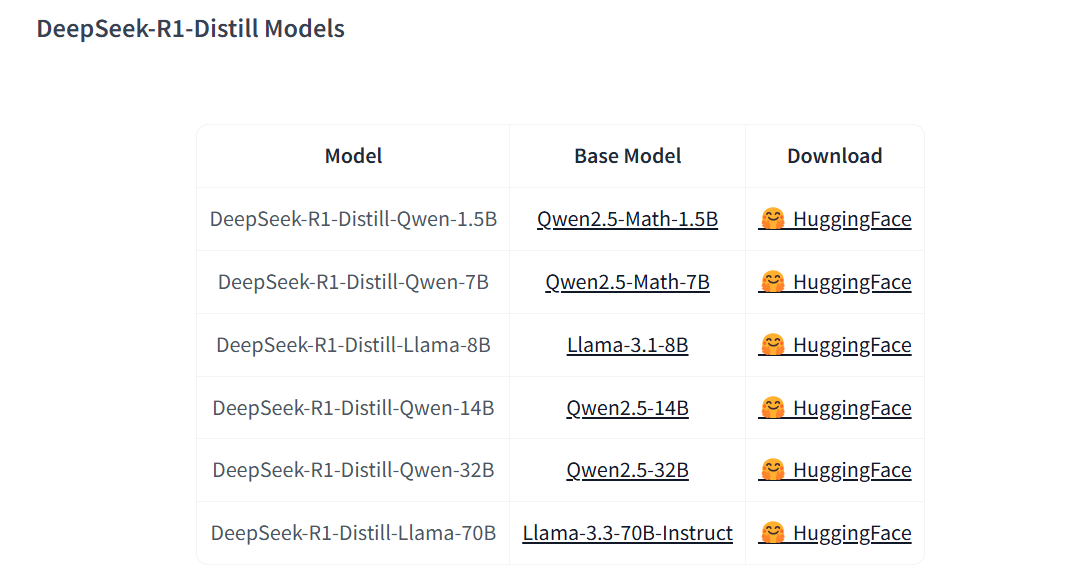
此外,DeepSeek-AI 还研究了模型蒸馏技术,将 DeepSeek-R1 的推理能力迁移至更小的模型(1.5B 至 70B),这些蒸馏模型在多个推理基准测试上超越了 Qwen 和 Llama 现有的开源模型。
该研究的最大亮点在于:
- 首次通过纯强化学习训练模型,无需监督微调,即可发展强大推理能力。
- 引入冷启动数据与多阶段强化学习,使推理能力更具可读性和一致性。
- 蒸馏方法证明了推理能力可以被迁移至小型模型,降低计算成本的同时保持高性能。
DeepSeek-R1 的发布不仅推动了大语言模型在推理能力上的进化,也为开源 AI 社区提供了更具竞争力的模型选择。论文开源了多个版本的 DeepSeek-R1 及其蒸馏模型,助力学术研究与工业应用的进一步发展。
这项研究意味着什么?DeepSeek-R1 如何改变大模型推理的未来?欢迎阅读本文,一探究竟!
1.DeepSeek系列模型的演进
DeepSeek-AI 团队在推进 DeepSeek-R1 模型的同时,已经发布了多个版本的模型,每一个版本都标志着技术的进步和推理能力的不断提升。以下是 DeepSeek 系列模型的重要演进:
- 2024年1月,DeepSeek 团队发布了 DeepSeekMoE 系列,其中最大的版本拥有 67B 参数,采用了混合专家模型(MoE)架构。通过精细化的 Expert 模块,DeepSeekMoE 在训练和生成过程中显著减少了计算资源的消耗,并且取得了更加稳定的推理效果。
- 2024年5月,发布了 DeepSeek-v2,该版本引入了多头潜在注意力机制(MLA)。这一创新显著降低了推理阶段的显卡缓存占用,使得模型能够更高效地进行推理任务,同时将生成文本的成本大幅降低。
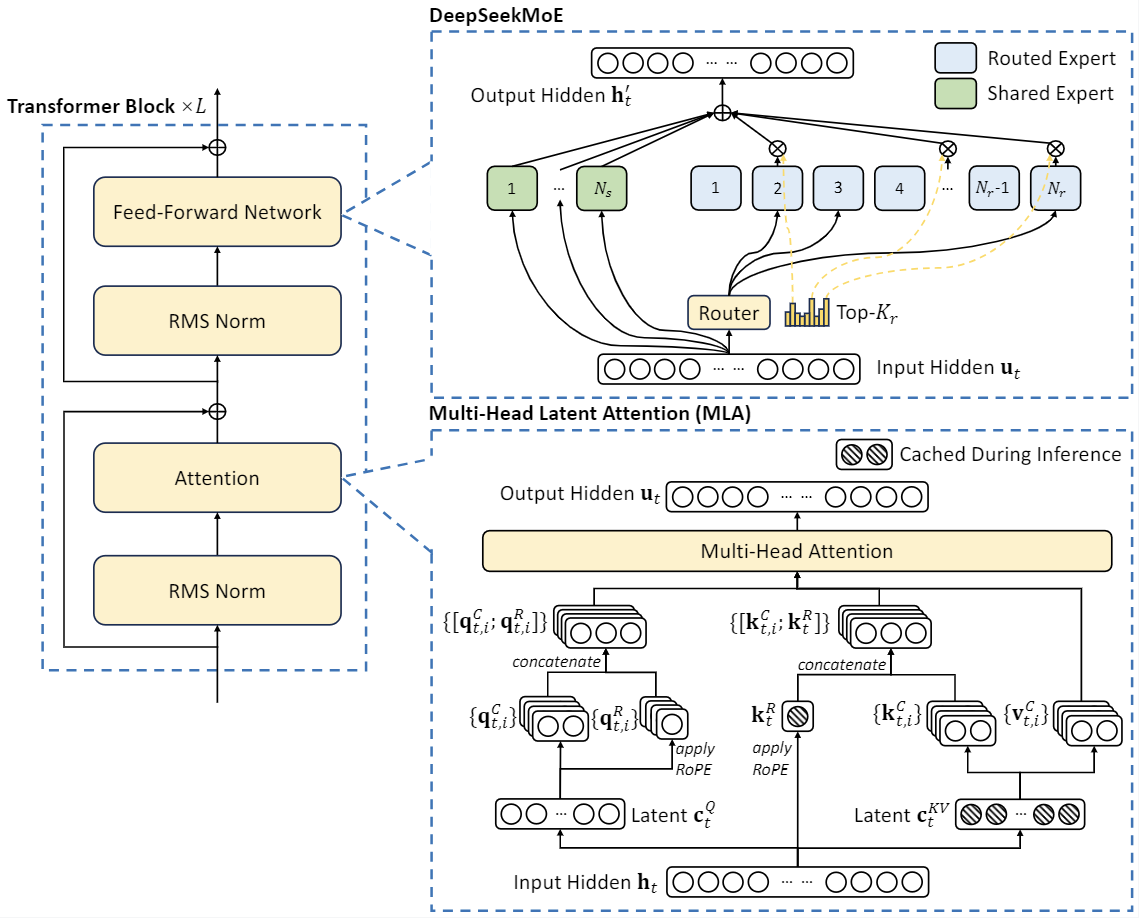
- 2024年12月,发布了 DeepSeek-v3,该版本拥有 671B 的参数,采用了多token预测训练(MTP)技术和无损负载均衡技术。通过这些技术,DeepSeek-v3 在训练过程中大幅提升了模型能力,最终使得该模型与 GPT-4o 的最新版本相媲美。
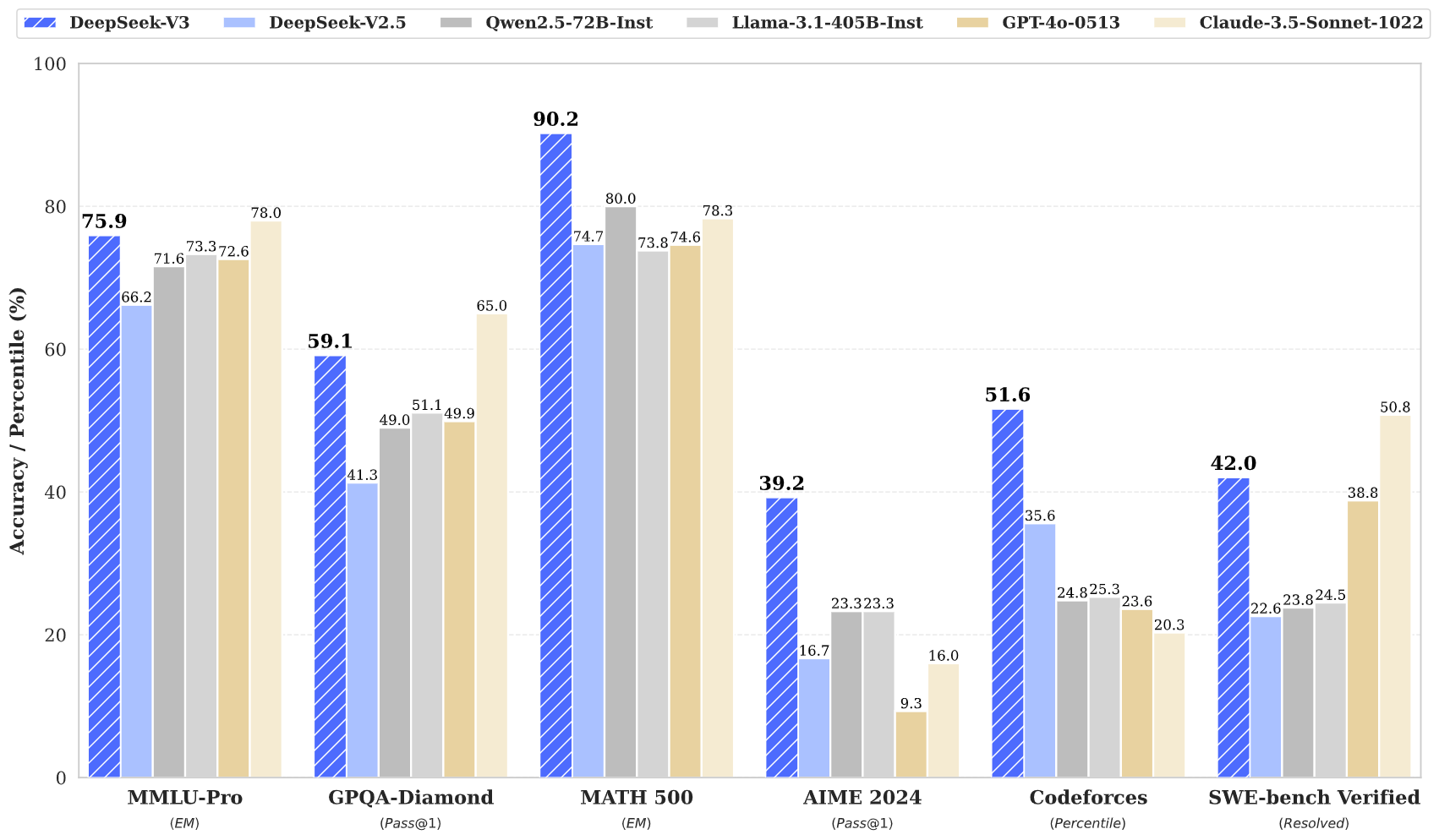
2. 技术特点
2.1 DeepSeek-R1-Zero与强化学习
DeepSeek-R1-Zero 是第一个完全通过强化学习训练的大语言模型,表现出色的推理能力令研究人员惊叹。在训练过程中,模型通过自我优化和自我评估,学习了如何解决复杂的推理任务。这种强化学习方法不仅降低了依赖监督学习的成本,而且使模型在推理过程中产生了“顿悟时刻”,即模型会重新评估并优化其推理路径。

Table 3展示了 DeepSeek-R1-Zero 在强化学习过程中自我优化的推理流程,突出了模型在推理任务中的“顿悟时刻”。
2.2 冷启动数据与多阶段训练
为了解决 DeepSeek-R1-Zero 在可读性和语言一致性方面的问题,DeepSeek 团队引入了冷启动数据和多阶段训练方法。这一优化使得 DeepSeek-R1 在推理任务中达到了 OpenAI o1-1217 的水平,并且增强了模型的可读性。
Figure 1对比了 DeepSeek-R1 和 DeepSeek-R1-Zero 在推理任务中的表现,突出展示了引入冷启动数据和多阶段训练后模型推理能力的显著提升。
2.3 蒸馏技术
蒸馏技术在 DeepSeek-R1 模型的应用中同样起到了关键作用。通过将大模型的推理能力迁移到小型模型,DeepSeek 团队成功地提高了小型模型在推理任务中的表现,同时减少了计算资源的消耗。特别是,DeepSeek-R1 的蒸馏模型在多个推理基准测试中超越了 Qwen 和 Llama 等现有开源模型。
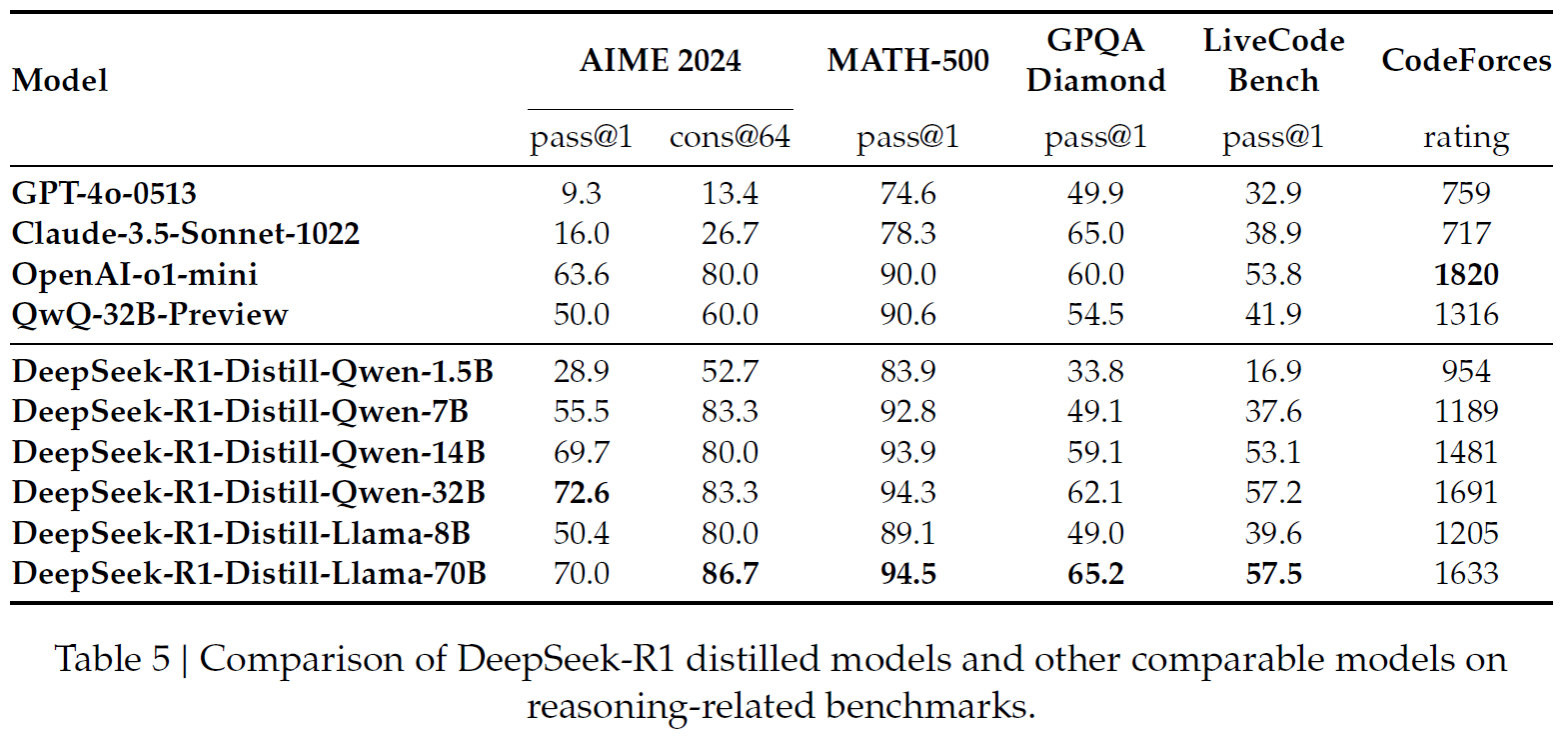
Table 5展示了 DeepSeek-R1 蒸馏后的模型在多个推理基准测试中的表现,突显了蒸馏技术的有效性和对小型模型推理能力的提升。
2.4 应用场景
DeepSeek-R1 模型不仅在推理任务上取得了显著进展,还在多个应用场景中展现了其强大的能力,包括但不限于:
- 编程任务:包括代码生成、算法设计等。
- 数学推理:通过对复杂数学问题的求解展现了模型的数学推理能力。
- 科学推理:在涉及科学问题的推理任务中,DeepSeek-R1 能够处理需要高度逻辑推理的场景。
- 开放领域问答:在多任务的开放领域问答中,DeepSeek-R1 提供了准确且一致的答案。
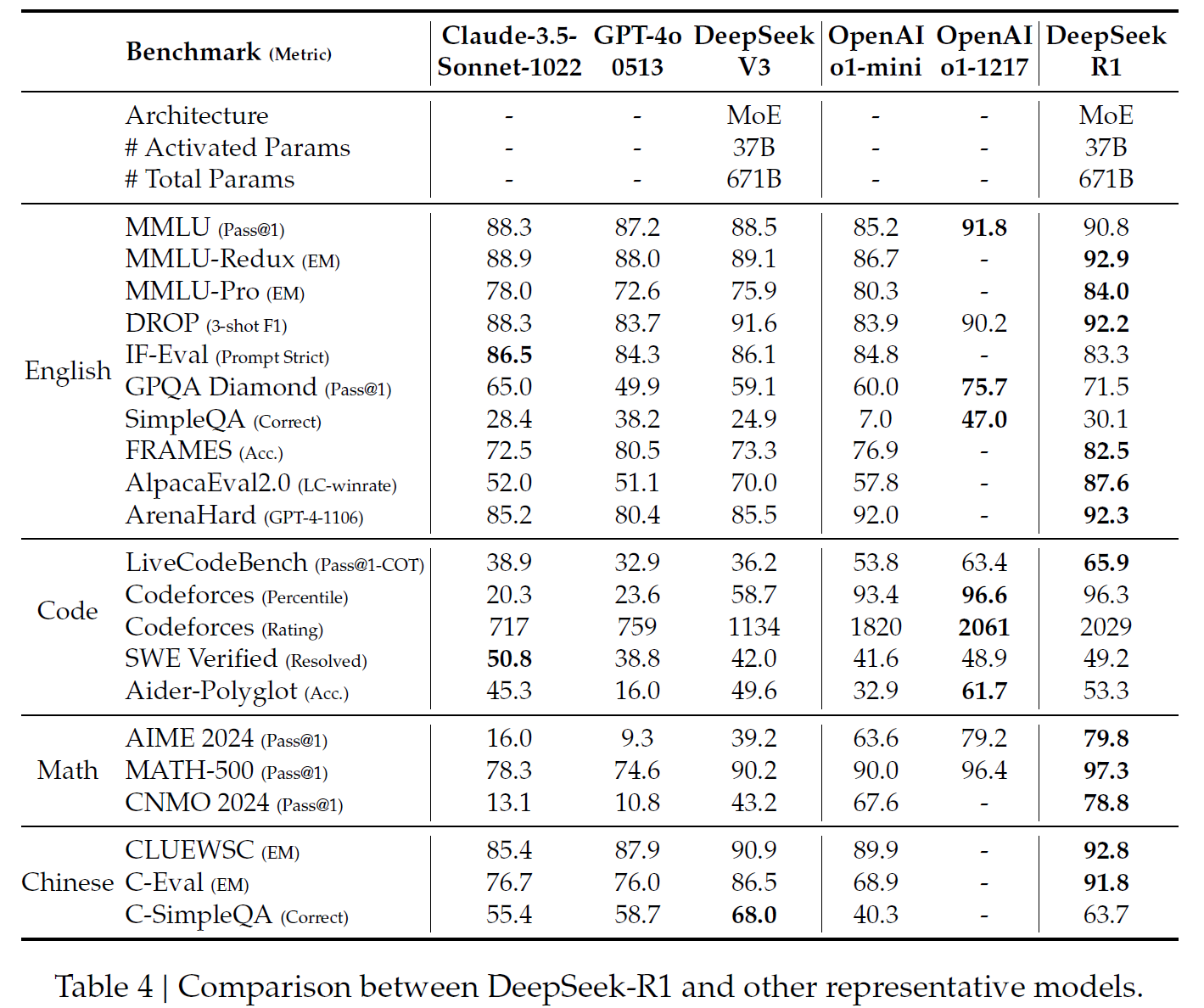
3. 未来展望
随着 DeepSeek-R1 模型的不断优化和应用,团队计划进一步提高模型的推理能力,特别是在长链推理(CoT)和复杂多轮对话中的表现。同时,未来的研究还将探索如何通过进一步的蒸馏和强化学习方法,提升小型模型的推理能力和应用范围。
总结
DeepSeek-R1 的发布标志着大语言模型推理能力的一个重要突破。通过强化学习、冷启动数据、多阶段训练以及蒸馏技术的创新应用,DeepSeek-AI 不仅在多个领域提升了模型的推理表现,还为开源 AI 社区提供了更具竞争力的研究工具。随着技术的不断发展,DeepSeek-R1 有望在更多实际应用中发挥巨大潜力,并为全球 AI 研究和应用提供新的思路和方向。
参考文献
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., … & He, Y. (2025). Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948.
 微信
微信 支付宝
支付宝

